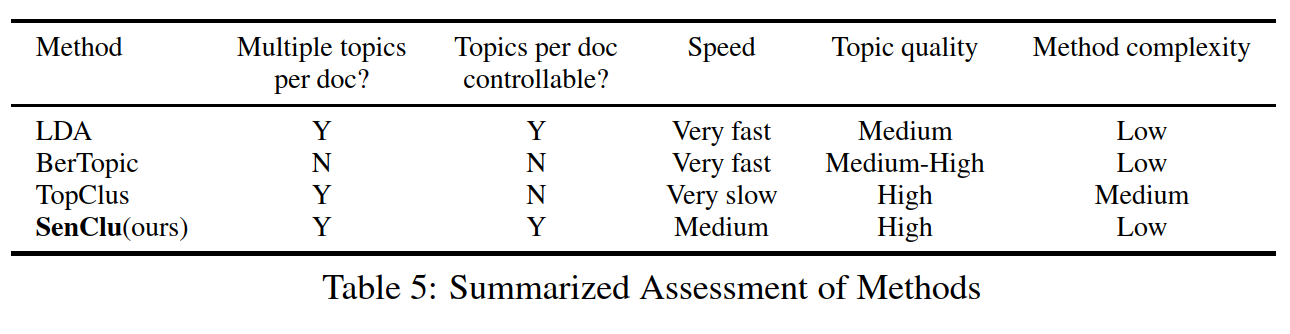
Topic Modeling based on Keywords and Context
Current topic models often suffer from discovering topics not matching human intuition, unnatural switching of topics within documents and high computational demands. We address these concerns by proposing a topic model and an inference algorithm based on automatically identifying characteristic keywords for topics. Keywords influence topic-assignments of nearby words. Our algorithm learns (key)word-topic scores and it self-regulates the number of topics. Inference is simple and easily parallelizable. Qualitative analysis yields comparable results to state-of-the-art models (eg. LDA), but with different strengths and weaknesses. Quantitative analysis using 9 datasets shows gains in terms of classification accuracy, PMI score, computational performance and consistency of topic assignments within documents, while most often using less topics.
PDF Abstract


