Toward Building General Foundation Models for Language, Vision, and Vision-Language Understanding Tasks
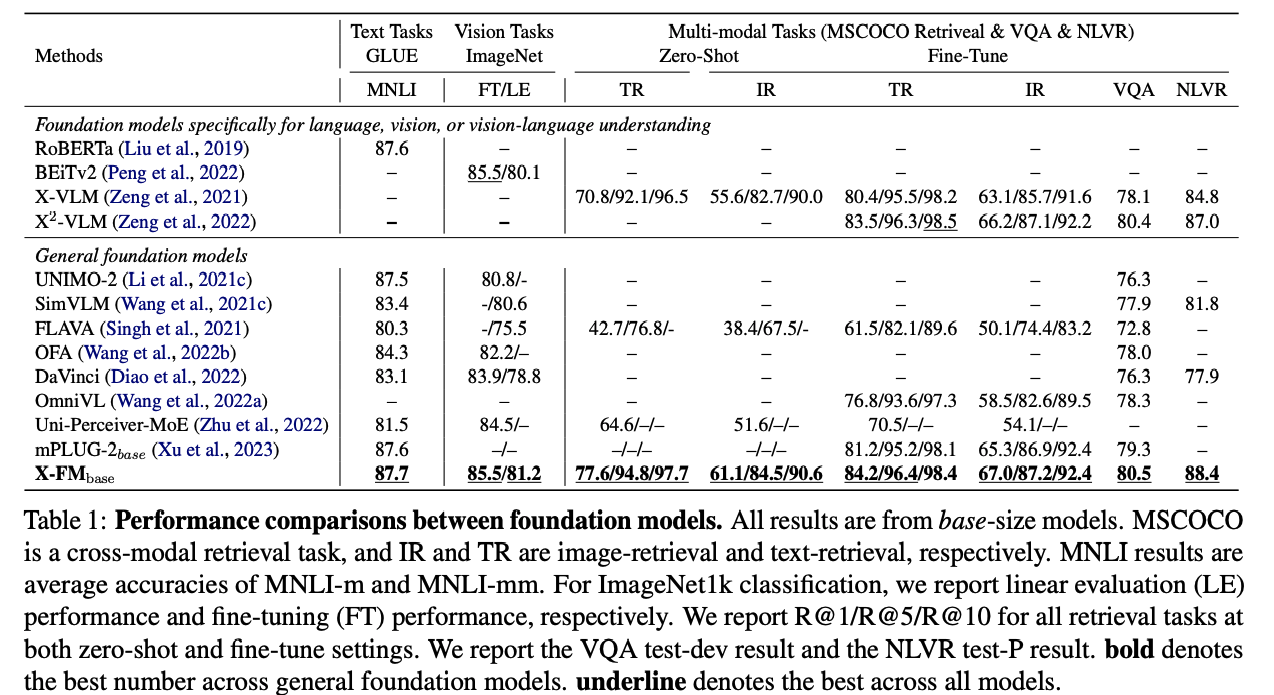
Foundation models or pre-trained models have substantially improved the performance of various language, vision, and vision-language understanding tasks. However, existing foundation models can only perform the best in one type of tasks, namely language, vision, or vision-language. It is still an open question whether it is possible to construct a foundation model performing the best for all the understanding tasks, which we call a general foundation model. In this paper, we propose a new general foundation model, X-FM (the X-Foundation Model). X-FM has one language encoder, one vision encoder, and one fusion encoder, as well as a new training method. The training method includes two new techniques for learning X-FM from text, image, and image-text pair data. One is to stop gradients from the vision-language training when learning the language encoder. The other is to leverage the vision-language training to guide the learning of the vision encoder. Extensive experiments on benchmark datasets show that X-FM can significantly outperform existing general foundation models and perform better than or comparable to existing foundation models specifically for language, vision, or vision-language understanding. Code and pre-trained models are released at https://github.com/zhangxinsong-nlp/XFM.
PDF Abstract



 CIFAR-10
CIFAR-10
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 QNLI
QNLI
 Oxford 102 Flower
Oxford 102 Flower
 MRPC
MRPC
 DTD
DTD
 CoLA
CoLA
 Food-101
Food-101
 Visual Question Answering v2.0
Visual Question Answering v2.0
 RefCOCO
RefCOCO
 NLVR
NLVR

