Towards Learning a Generic Agent for Vision-and-Language Navigation via Pre-training
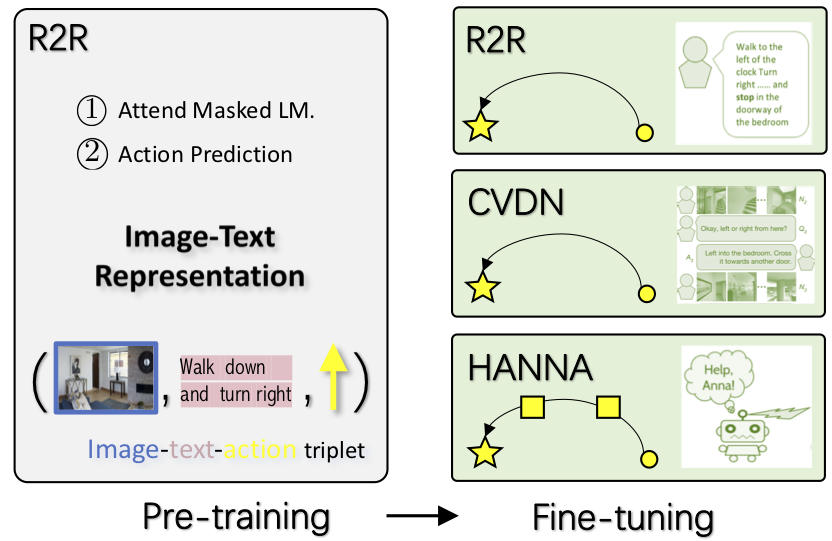
Learning to navigate in a visual environment following natural-language instructions is a challenging task, because the multimodal inputs to the agent are highly variable, and the training data on a new task is often limited. In this paper, we present the first pre-training and fine-tuning paradigm for vision-and-language navigation (VLN) tasks. By training on a large amount of image-text-action triplets in a self-supervised learning manner, the pre-trained model provides generic representations of visual environments and language instructions. It can be easily used as a drop-in for existing VLN frameworks, leading to the proposed agent called Prevalent. It learns more effectively in new tasks and generalizes better in a previously unseen environment. The performance is validated on three VLN tasks. On the Room-to-Room benchmark, our model improves the state-of-the-art from 47% to 51% on success rate weighted by path length. Further, the learned representation is transferable to other VLN tasks. On two recent tasks, vision-and-dialog navigation and "Help, Anna!" the proposed Prevalent leads to significant improvement over existing methods, achieving a new state of the art.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract

 R2R
R2R
 HELP
HELP

