Towards Robust Referring Image Segmentation
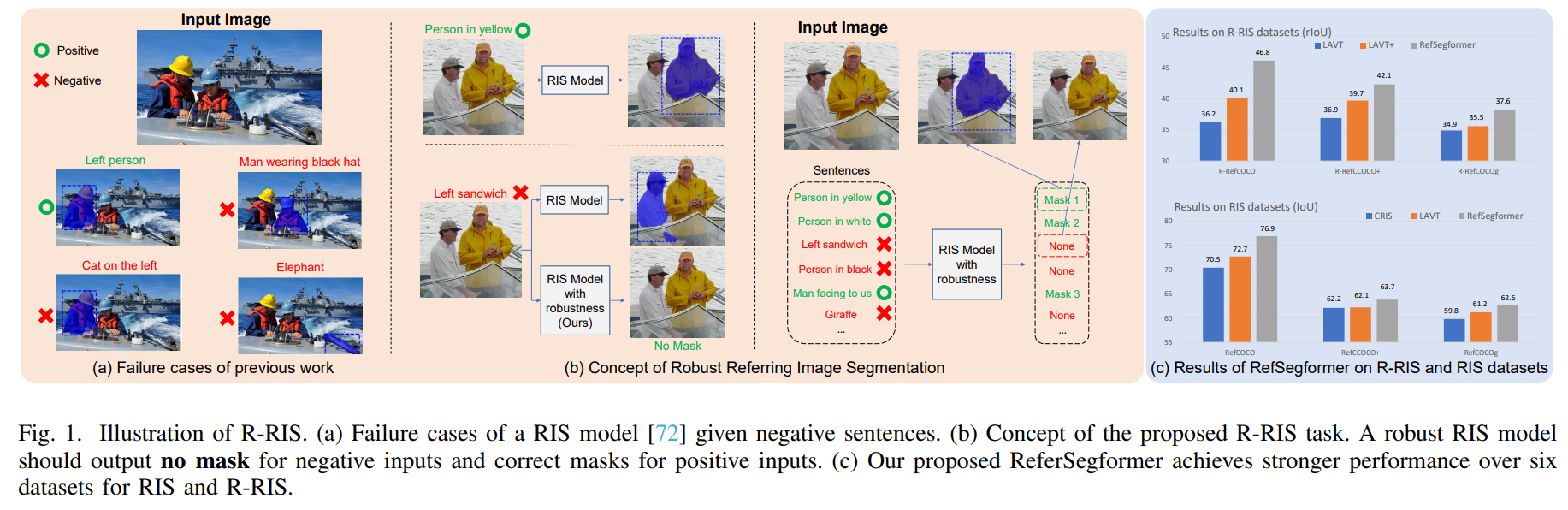
Referring Image Segmentation (RIS) is a fundamental vision-language task that outputs object masks based on text descriptions. Many works have achieved considerable progress for RIS, including different fusion method designs. In this work, we explore an essential question, ``What if the text description is wrong or misleading?'' For example, the described objects are not in the image. We term such a sentence as a negative sentence. However, existing solutions for RIS cannot handle such a setting. To this end, we propose a new formulation of RIS, named Robust Referring Image Segmentation (R-RIS). It considers the negative sentence inputs besides the regular positive text inputs. To facilitate this new task, we create three R-RIS datasets by augmenting existing RIS datasets with negative sentences and propose new metrics to evaluate both types of inputs in a unified manner. Furthermore, we propose a new transformer-based model, called RefSegformer, with a token-based vision and language fusion module. Our design can be easily extended to our R-RIS setting by adding extra blank tokens. Our proposed RefSegformer achieves state-of-the-art results on both RIS and R-RIS datasets, establishing a solid baseline for both settings. Our project page is at \url{https://github.com/jianzongwu/robust-ref-seg}.
PDF Abstract


 MS COCO
MS COCO
