Improving Anytime Prediction with Parallel Cascaded Networks and a Temporal-Difference Loss
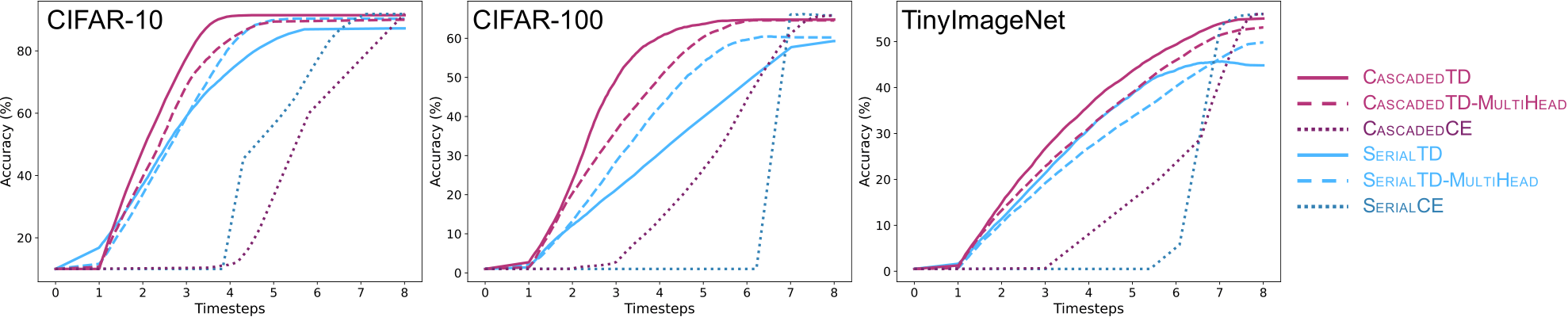
Although deep feedforward neural networks share some characteristics with the primate visual system, a key distinction is their dynamics. Deep nets typically operate in serial stages wherein each layer completes its computation before processing begins in subsequent layers. In contrast, biological systems have cascaded dynamics: information propagates from neurons at all layers in parallel but transmission occurs gradually over time, leading to speed-accuracy trade offs even in feedforward architectures. We explore the consequences of biologically inspired parallel hardware by constructing cascaded ResNets in which each residual block has propagation delays but all blocks update in parallel in a stateful manner. Because information transmitted through skip connections avoids delays, the functional depth of the architecture increases over time, yielding anytime predictions that improve with internal-processing time. We introduce a temporal-difference training loss that achieves a strictly superior speed-accuracy profile over standard losses and enables the cascaded architecture to outperform state-of-the-art anytime-prediction methods. The cascaded architecture has intriguing properties, including: it classifies typical instances more rapidly than atypical instances; it is more robust to both persistent and transient noise than is a conventional ResNet; and its time-varying output trace provides a signal that can be exploited to improve information processing and inference.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract
 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 LSUN
LSUN
