Transferable Clean-Label Poisoning Attacks on Deep Neural Nets
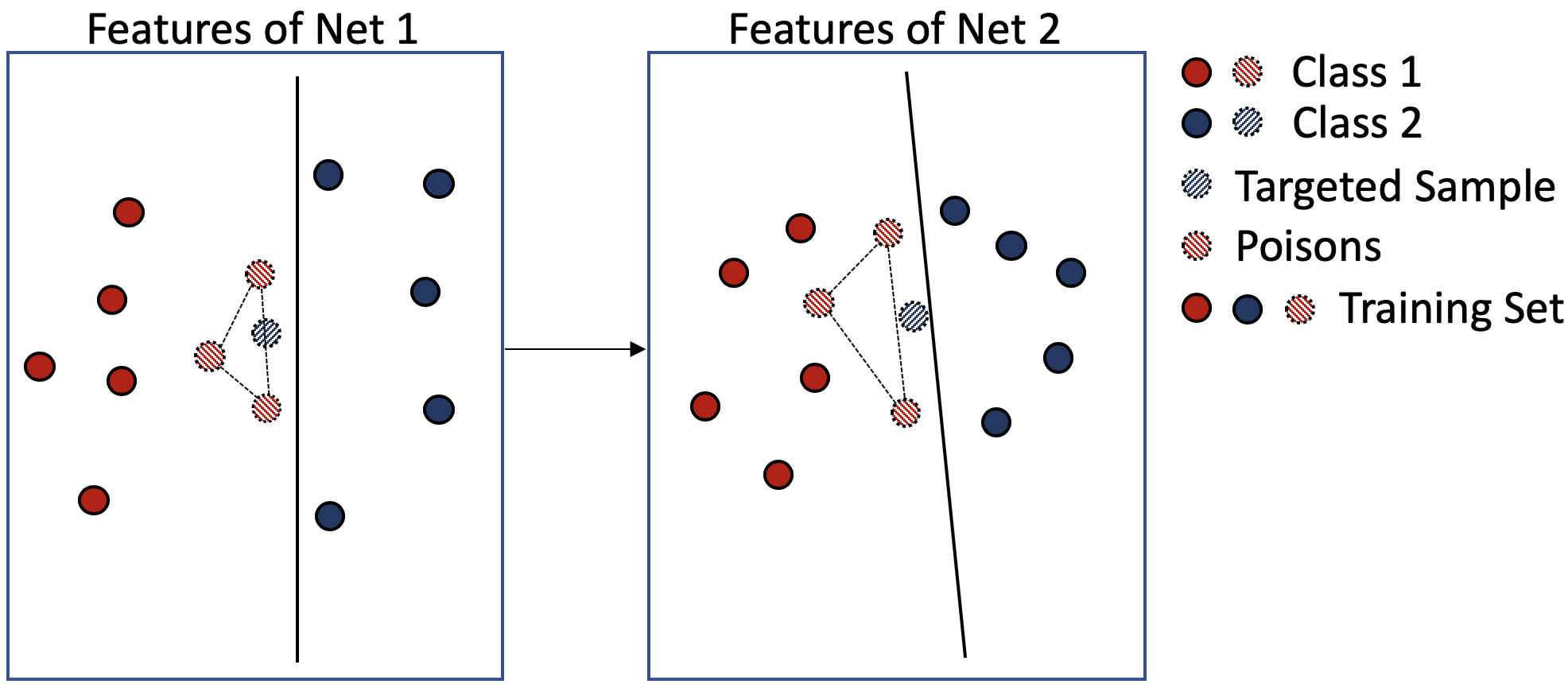
Clean-label poisoning attacks inject innocuous looking (and "correctly" labeled) poison images into training data, causing a model to misclassify a targeted image after being trained on this data. We consider transferable poisoning attacks that succeed without access to the victim network's outputs, architecture, or (in some cases) training data. To achieve this, we propose a new "polytope attack" in which poison images are designed to surround the targeted image in feature space. We also demonstrate that using Dropout during poison creation helps to enhance transferability of this attack. We achieve transferable attack success rates of over 50% while poisoning only 1% of the training set.
PDF Abstract
Tasks

Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
