TransZero: Attribute-guided Transformer for Zero-Shot Learning
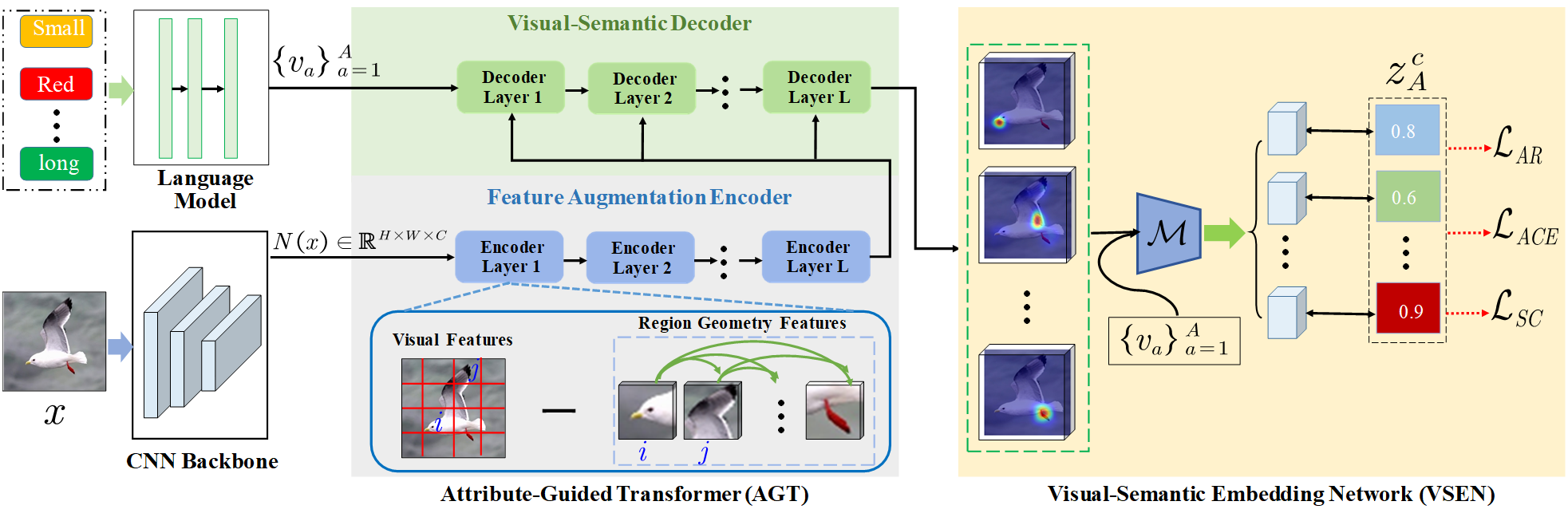
Zero-shot learning (ZSL) aims to recognize novel classes by transferring semantic knowledge from seen classes to unseen ones. Semantic knowledge is learned from attribute descriptions shared between different classes, which act as strong priors for localizing object attributes that represent discriminative region features, enabling significant visual-semantic interaction. Although some attention-based models have attempted to learn such region features in a single image, the transferability and discriminative attribute localization of visual features are typically neglected. In this paper, we propose an attribute-guided Transformer network, termed TransZero, to refine visual features and learn attribute localization for discriminative visual embedding representations in ZSL. Specifically, TransZero takes a feature augmentation encoder to alleviate the cross-dataset bias between ImageNet and ZSL benchmarks, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. To learn locality-augmented visual features, TransZero employs a visual-semantic decoder to localize the image regions most relevant to each attribute in a given image, under the guidance of semantic attribute information. Then, the locality-augmented visual features and semantic vectors are used to conduct effective visual-semantic interaction in a visual-semantic embedding network. Extensive experiments show that TransZero achieves the new state of the art on three ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero}.
PDF Abstract


 AwA
AwA
