Tree-Structured Policy based Progressive Reinforcement Learning for Temporally Language Grounding in Video
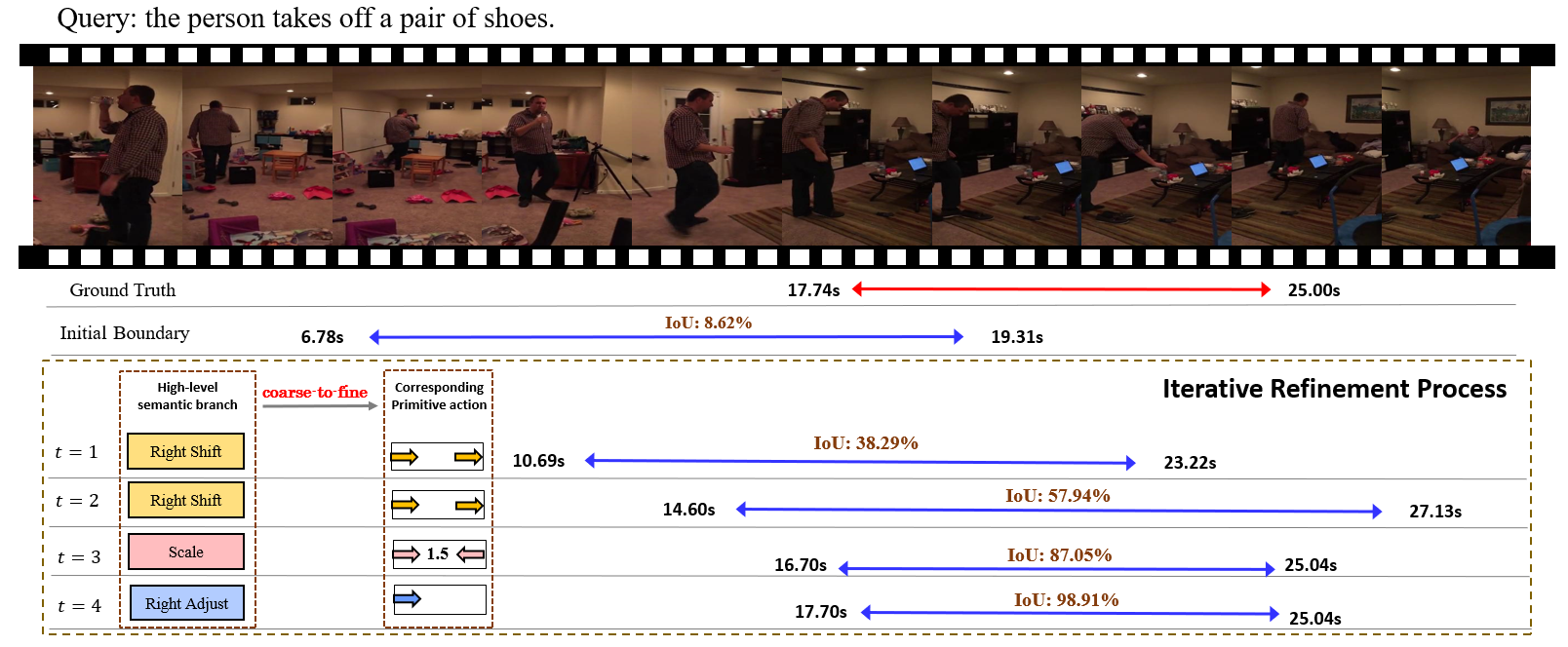
Temporally language grounding in untrimmed videos is a newly-raised task in video understanding. Most of the existing methods suffer from inferior efficiency, lacking interpretability, and deviating from the human perception mechanism. Inspired by human's coarse-to-fine decision-making paradigm, we formulate a novel Tree-Structured Policy based Progressive Reinforcement Learning (TSP-PRL) framework to sequentially regulate the temporal boundary by an iterative refinement process. The semantic concepts are explicitly represented as the branches in the policy, which contributes to efficiently decomposing complex policies into an interpretable primitive action. Progressive reinforcement learning provides correct credit assignment via two task-oriented rewards that encourage mutual promotion within the tree-structured policy. We extensively evaluate TSP-PRL on the Charades-STA and ActivityNet datasets, and experimental results show that TSP-PRL achieves competitive performance over existing state-of-the-art methods.
PDF Abstract

 Charades
Charades
 Charades-STA
Charades-STA
