TResNet: High Performance GPU-Dedicated Architecture
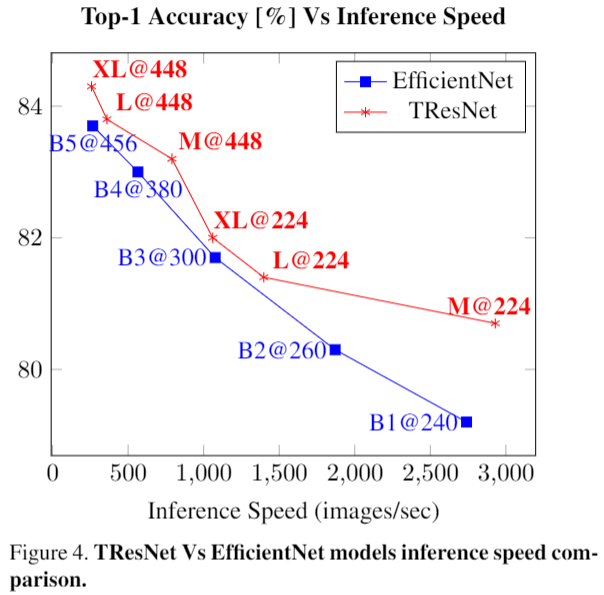
Many deep learning models, developed in recent years, reach higher ImageNet accuracy than ResNet50, with fewer or comparable FLOPS count. While FLOPs are often seen as a proxy for network efficiency, when measuring actual GPU training and inference throughput, vanilla ResNet50 is usually significantly faster than its recent competitors, offering better throughput-accuracy trade-off. In this work, we introduce a series of architecture modifications that aim to boost neural networks' accuracy, while retaining their GPU training and inference efficiency. We first demonstrate and discuss the bottlenecks induced by FLOPs-optimizations. We then suggest alternative designs that better utilize GPU structure and assets. Finally, we introduce a new family of GPU-dedicated models, called TResNet, which achieve better accuracy and efficiency than previous ConvNets. Using a TResNet model, with similar GPU throughput to ResNet50, we reach 80.8 top-1 accuracy on ImageNet. Our TResNet models also transfer well and achieve state-of-the-art accuracy on competitive single-label classification datasets such as Stanford cars (96.0%), CIFAR-10 (99.0%), CIFAR-100 (91.5%) and Oxford-Flowers (99.1%). They also perform well on multi-label classification and object detection tasks. Implementation is available at: https://github.com/mrT23/TResNet.
PDF AbstractCode






Datasets
 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
Results from the Paper
 Ranked #7 on
Fine-Grained Image Classification
on Oxford 102 Flowers
(using extra training data)
Ranked #7 on
Fine-Grained Image Classification
on Oxford 102 Flowers
(using extra training data)
