UAVM: Towards Unifying Audio and Visual Models
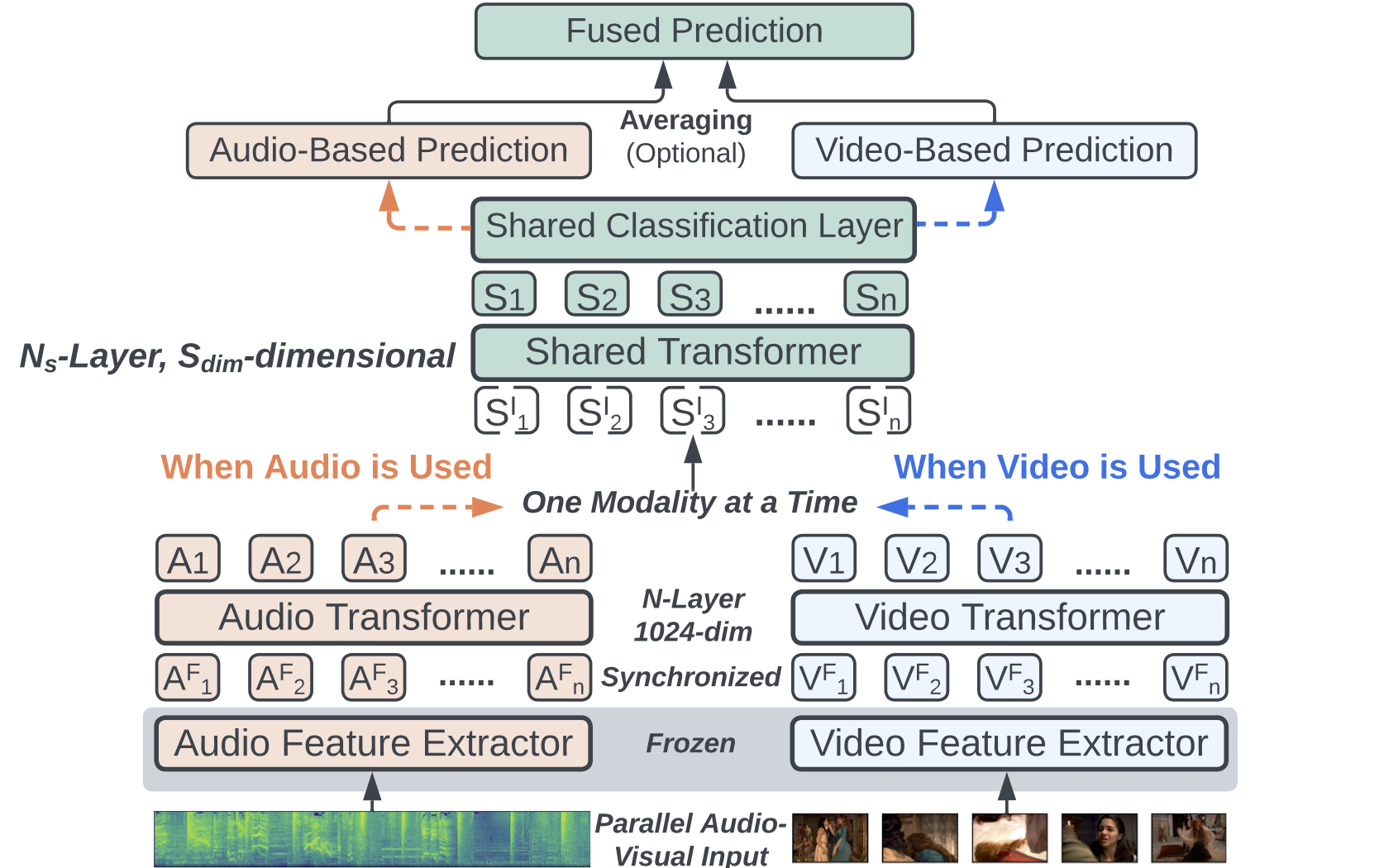
Conventional audio-visual models have independent audio and video branches. In this work, we unify the audio and visual branches by designing a Unified Audio-Visual Model (UAVM). The UAVM achieves a new state-of-the-art audio-visual event classification accuracy of 65.8% on VGGSound. More interestingly, we also find a few intriguing properties of UAVM that the modality-independent counterparts do not have.
PDF AbstractCode


 AudioSet
AudioSet
 VGG-Sound
VGG-Sound
Results from the Paper
 Ranked #2 on
Multi-modal Classification
on AudioSet
(using extra training data)
Ranked #2 on
Multi-modal Classification
on AudioSet
(using extra training data)
