Understanding and Improving Transformer From a Multi-Particle Dynamic System Point of View
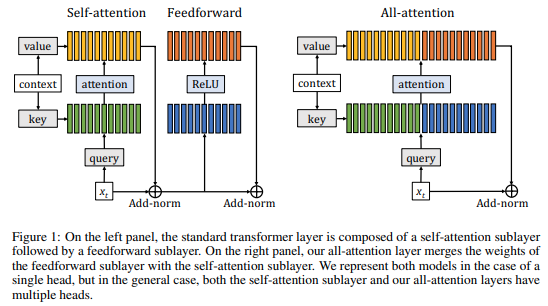
The Transformer architecture is widely used in natural language processing. Despite its success, the design principle of the Transformer remains elusive. In this paper, we provide a novel perspective towards understanding the architecture: we show that the Transformer can be mathematically interpreted as a numerical Ordinary Differential Equation (ODE) solver for a convection-diffusion equation in a multi-particle dynamic system. In particular, how words in a sentence are abstracted into contexts by passing through the layers of the Transformer can be interpreted as approximating multiple particles' movement in the space using the Lie-Trotter splitting scheme and the Euler's method. Given this ODE's perspective, the rich literature of numerical analysis can be brought to guide us in designing effective structures beyond the Transformer. As an example, we propose to replace the Lie-Trotter splitting scheme by the Strang-Marchuk splitting scheme, a scheme that is more commonly used and with much lower local truncation errors. The Strang-Marchuk splitting scheme suggests that the self-attention and position-wise feed-forward network (FFN) sub-layers should not be treated equally. Instead, in each layer, two position-wise FFN sub-layers should be used, and the self-attention sub-layer is placed in between. This leads to a brand new architecture. Such an FFN-attention-FFN layer is "Macaron-like", and thus we call the network with this new architecture the Macaron Net. Through extensive experiments, we show that the Macaron Net is superior to the Transformer on both supervised and unsupervised learning tasks. The reproducible codes and pretrained models can be found at https://github.com/zhuohan123/macaron-net
PDF Abstract ICLR 2020 PDF ICLR 2020 Abstract


 GLUE
GLUE
 SST
SST
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
