Understanding Generalization in Adversarial Training via the Bias-Variance Decomposition
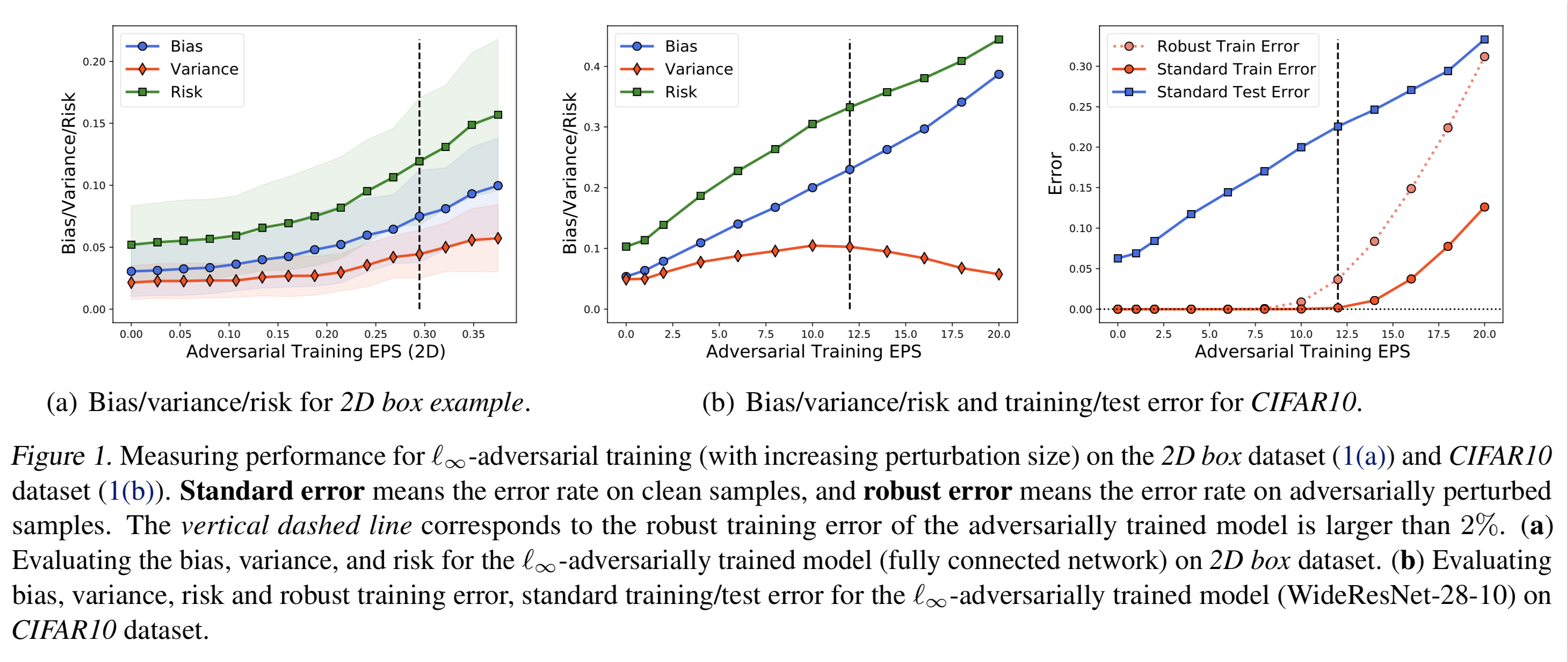
Adversarially trained models exhibit a large generalization gap: they can interpolate the training set even for large perturbation radii, but at the cost of large test error on clean samples. To investigate this gap, we decompose the test risk into its bias and variance components and study their behavior as a function of adversarial training perturbation radii ($\varepsilon$). We find that the bias increases monotonically with $\varepsilon$ and is the dominant term in the risk. Meanwhile, the variance is unimodal as a function of $\varepsilon$, peaking near the interpolation threshold for the training set. This characteristic behavior occurs robustly across different datasets and also for other robust training procedures such as randomized smoothing. It thus provides a test for proposed explanations of the generalization gap. We find that some existing explanations fail this test--for instance, by predicting a monotonically increasing variance curve. This underscores the power of bias-variance decompositions in modern settings-by providing two measurements instead of one, they can rule out more explanations than test accuracy alone. We also show that bias and variance can provide useful guidance for scalably reducing the generalization gap, highlighting pre-training and unlabeled data as promising routes.
PDF Abstract
 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
