Unified Vision and Language Prompt Learning
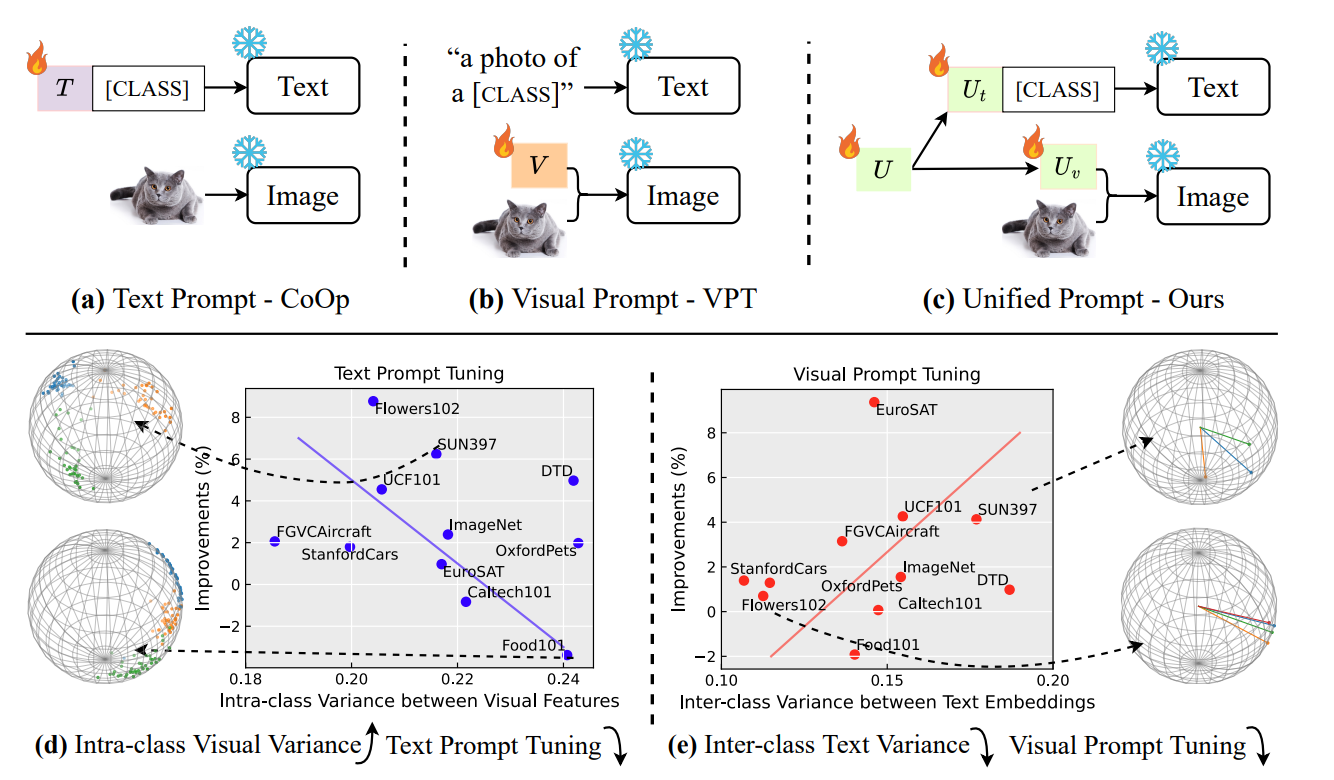
Prompt tuning, a parameter- and data-efficient transfer learning paradigm that tunes only a small number of parameters in a model's input space, has become a trend in the vision community since the emergence of large vision-language models like CLIP. We present a systematic study on two representative prompt tuning methods, namely text prompt tuning and visual prompt tuning. A major finding is that none of the unimodal prompt tuning methods performs consistently well: text prompt tuning fails on data with high intra-class visual variances while visual prompt tuning cannot handle low inter-class variances. To combine the best from both worlds, we propose a simple approach called Unified Prompt Tuning (UPT), which essentially learns a tiny neural network to jointly optimize prompts across different modalities. Extensive experiments on over 11 vision datasets show that UPT achieves a better trade-off than the unimodal counterparts on few-shot learning benchmarks, as well as on domain generalization benchmarks. Code and models will be released to facilitate future research.
PDF Abstract

 ImageNet
ImageNet
 UCF101
UCF101
 Oxford 102 Flower
Oxford 102 Flower
 Stanford Cars
Stanford Cars
 DTD
DTD
 Food-101
Food-101
 Caltech-101
Caltech-101
 EuroSAT
EuroSAT
 FGVC-Aircraft
FGVC-Aircraft
