Unifying Global-Local Representations in Salient Object Detection with Transformer
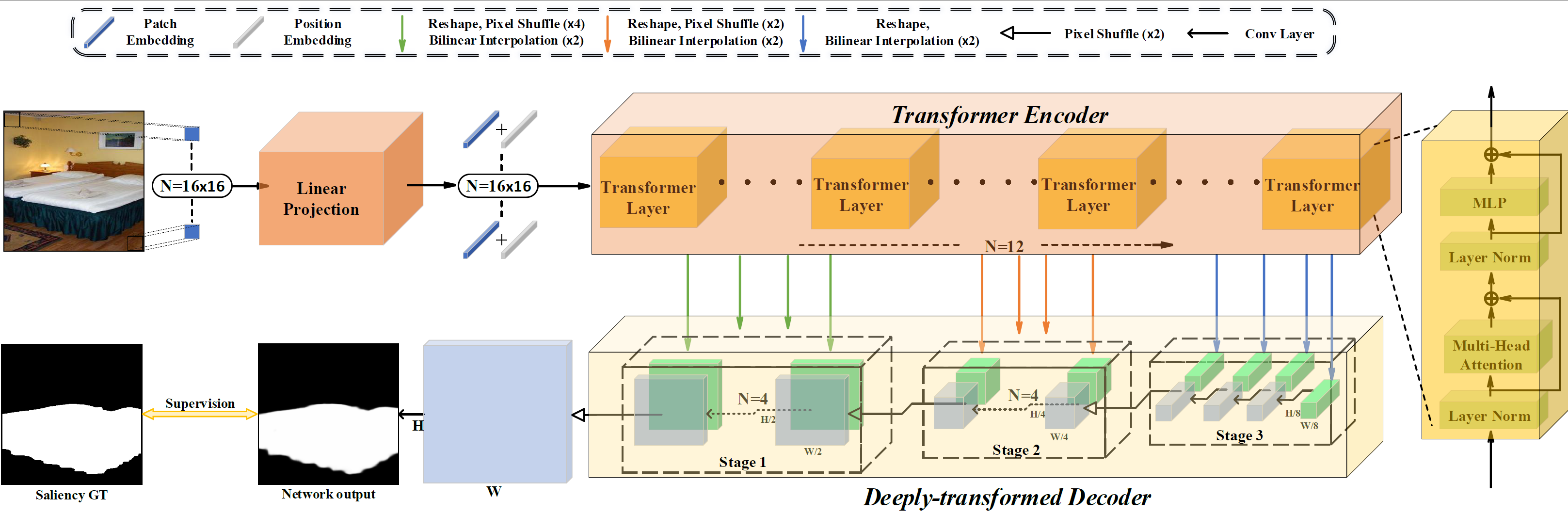
The fully convolutional network (FCN) has dominated salient object detection for a long period. However, the locality of CNN requires the model deep enough to have a global receptive field and such a deep model always leads to the loss of local details. In this paper, we introduce a new attention-based encoder, vision transformer, into salient object detection to ensure the globalization of the representations from shallow to deep layers. With the global view in very shallow layers, the transformer encoder preserves more local representations to recover the spatial details in final saliency maps. Besides, as each layer can capture a global view of its previous layer, adjacent layers can implicitly maximize the representation differences and minimize the redundant features, making that every output feature of transformer layers contributes uniquely for final prediction. To decode features from the transformer, we propose a simple yet effective deeply-transformed decoder. The decoder densely decodes and upsamples the transformer features, generating the final saliency map with less noise injection. Experimental results demonstrate that our method significantly outperforms other FCN-based and transformer-based methods in five benchmarks by a large margin, with an average of 12.17% improvement in terms of Mean Absolute Error (MAE). Code will be available at https://github.com/OliverRensu/GLSTR.
PDF Abstract


 PASCAL-S
PASCAL-S
 DUTS
DUTS
 HKU-IS
HKU-IS
 DUT-OMRON
DUT-OMRON
