UniMoCo: Unsupervised, Semi-Supervised and Full-Supervised Visual Representation Learning
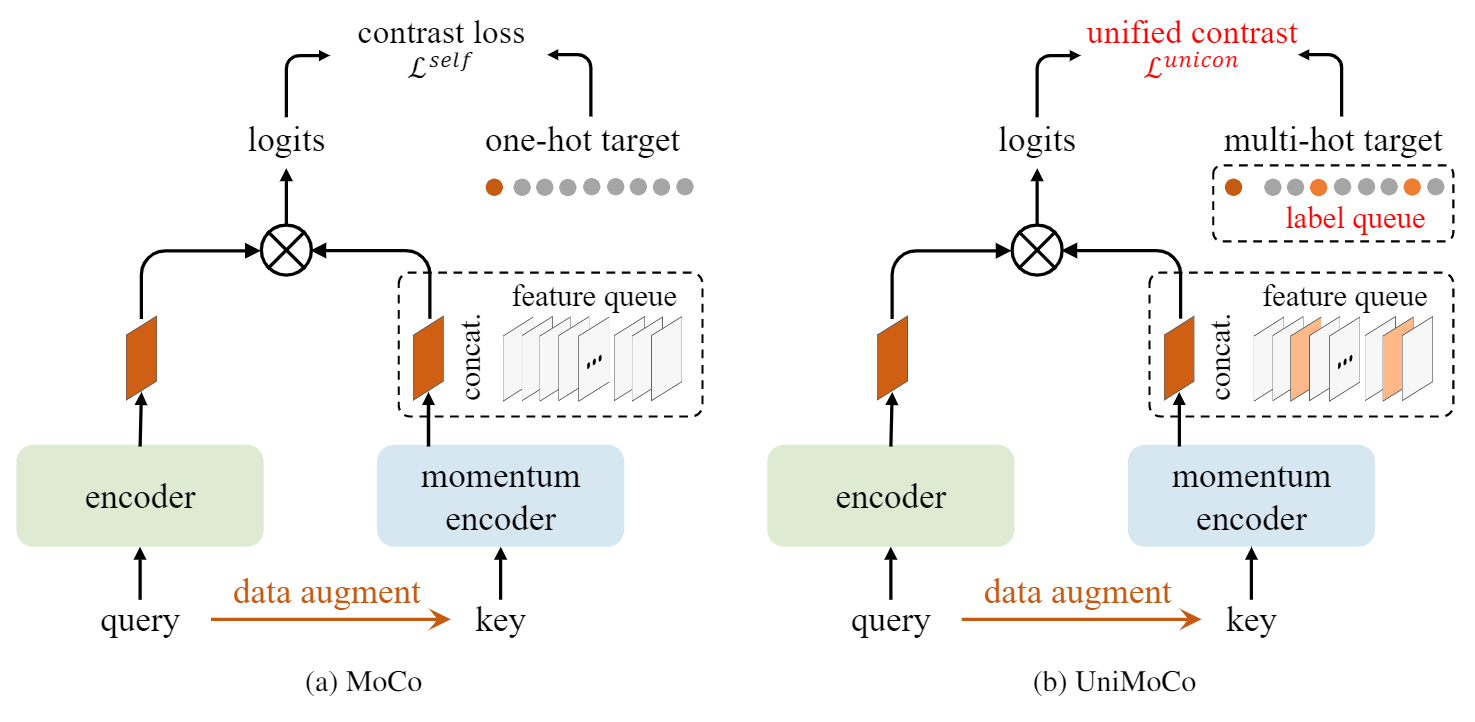
Momentum Contrast (MoCo) achieves great success for unsupervised visual representation. However, there are a lot of supervised and semi-supervised datasets, which are already labeled. To fully utilize the label annotations, we propose Unified Momentum Contrast (UniMoCo), which extends MoCo to support arbitrary ratios of labeled data and unlabeled data training. Compared with MoCo, UniMoCo has two modifications as follows: (1) Different from a single positive pair in MoCo, we maintain multiple positive pairs on-the-fly by comparing the query label to a label queue. (2) We propose a Unified Contrastive(UniCon) loss to support an arbitrary number of positives and negatives in a unified pair-wise optimization perspective. Our UniCon is more reasonable and powerful than the supervised contrastive loss in theory and practice. In our experiments, we pre-train multiple UniMoCo models with different ratios of ImageNet labels and evaluate the performance on various downstream tasks. Experiment results show that UniMoCo generalizes well for unsupervised, semi-supervised and supervised visual representation learning.
PDF Abstract

 ImageNet
ImageNet
 MS COCO
MS COCO
