UniParma at SemEval-2021 Task 5: Toxic Spans Detection Using CharacterBERT and Bag-of-Words Model
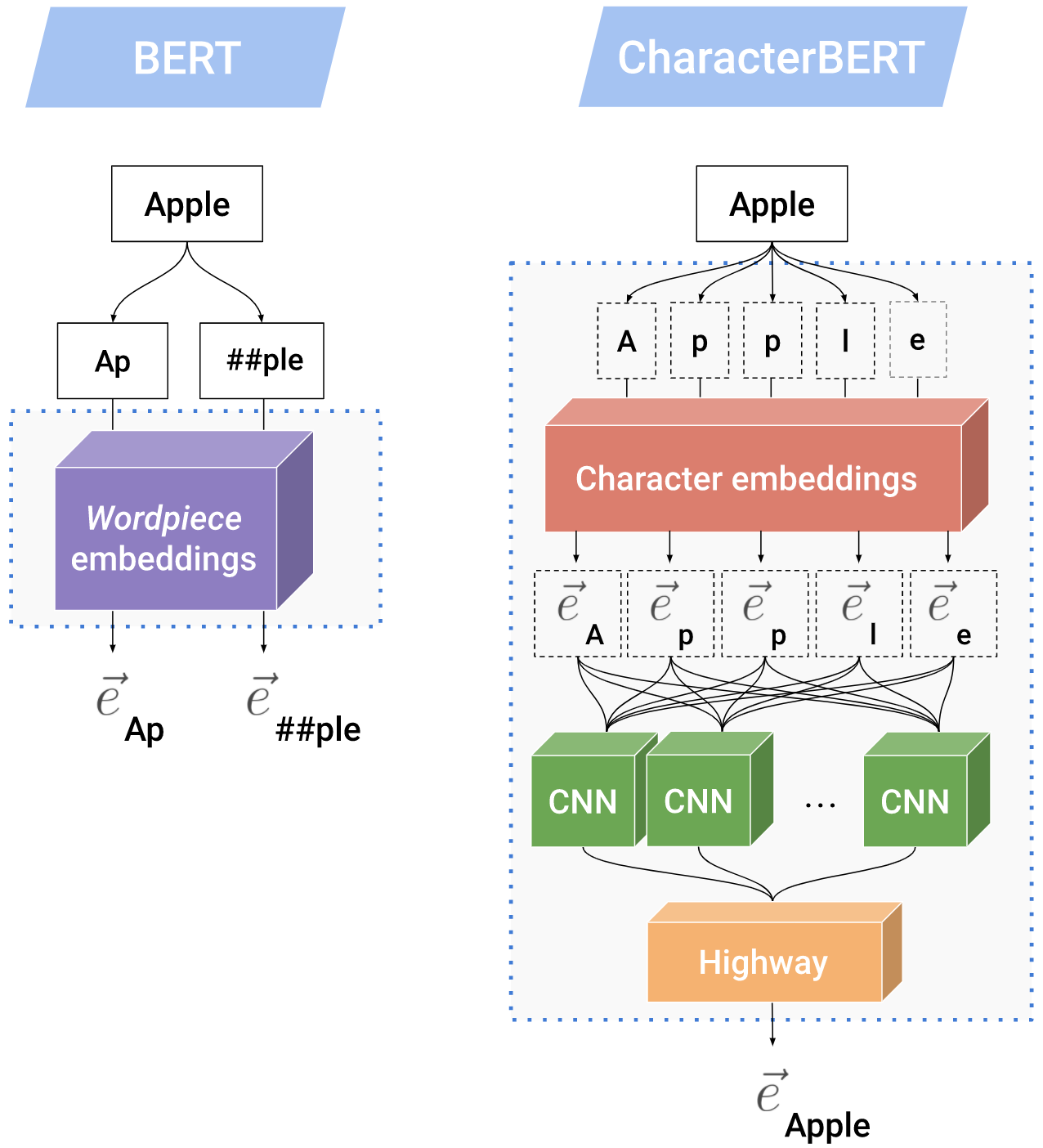
With the ever-increasing availability of digital information, toxic content is also on the rise. Therefore, the detection of this type of language is of paramount importance. We tackle this problem utilizing a combination of a state-of-the-art pre-trained language model (CharacterBERT) and a traditional bag-of-words technique. Since the content is full of toxic words that have not been written according to their dictionary spelling, attendance to individual characters is crucial. Therefore, we use CharacterBERT to extract features based on the word characters. It consists of a CharacterCNN module that learns character embeddings from the context. These are, then, fed into the well-known BERT architecture. The bag-of-words method, on the other hand, further improves upon that by making sure that some frequently used toxic words get labeled accordingly. With a 4 percent difference from the first team, our system ranked 36th in the competition. The code is available for further re-search and reproduction of the results.
PDF Abstract SEMEVAL 2021 PDF SEMEVAL 2021 Abstract


