Universal Litmus Patterns: Revealing Backdoor Attacks in CNNs
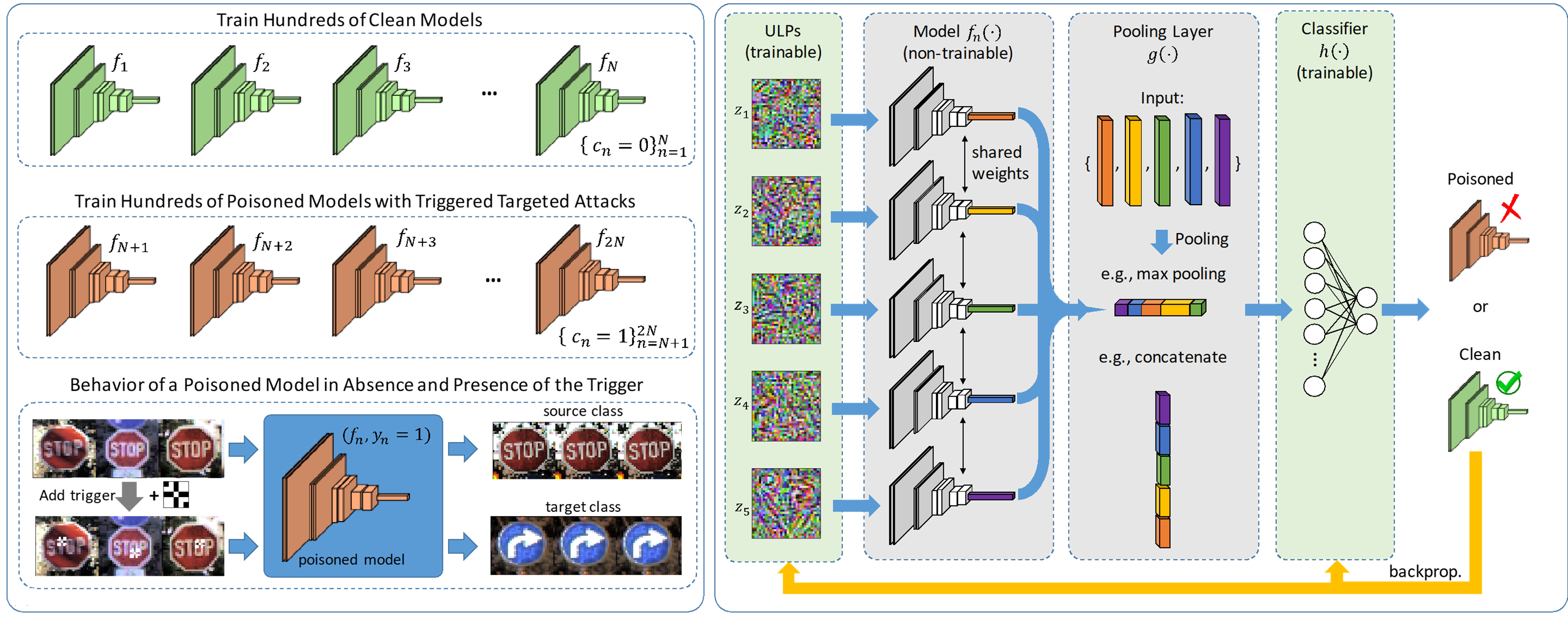
The unprecedented success of deep neural networks in many applications has made these networks a prime target for adversarial exploitation. In this paper, we introduce a benchmark technique for detecting backdoor attacks (aka Trojan attacks) on deep convolutional neural networks (CNNs). We introduce the concept of Universal Litmus Patterns (ULPs), which enable one to reveal backdoor attacks by feeding these universal patterns to the network and analyzing the output (i.e., classifying the network as `clean' or `corrupted'). This detection is fast because it requires only a few forward passes through a CNN. We demonstrate the effectiveness of ULPs for detecting backdoor attacks on thousands of networks with different architectures trained on four benchmark datasets, namely the German Traffic Sign Recognition Benchmark (GTSRB), MNIST, CIFAR10, and Tiny-ImageNet. The codes and train/test models for this paper can be found here https://umbcvision.github.io/Universal-Litmus-Patterns/.
PDF Abstract CVPR 2020 PDF CVPR 2020 Abstract

 CIFAR-10
CIFAR-10
 MNIST
MNIST
 GTSRB
GTSRB
