Unpaired Speech Enhancement by Acoustic and Adversarial Supervision for Speech Recognition
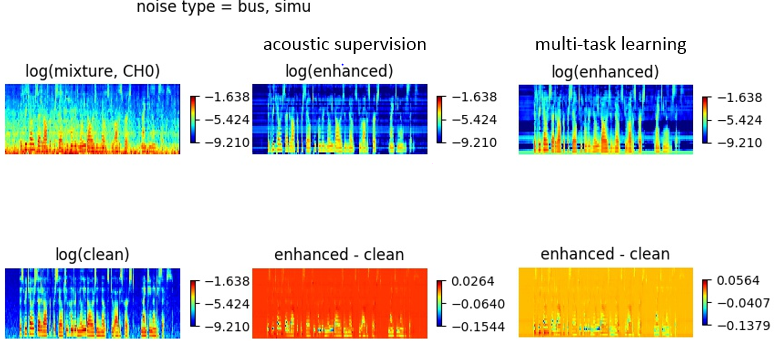
Many speech enhancement methods try to learn the relationship between noisy and clean speech, obtained using an acoustic room simulator. We point out several limitations of enhancement methods relying on clean speech targets; the goal of this work is proposing an alternative learning algorithm, called acoustic and adversarial supervision (AAS). AAS makes the enhanced output both maximizing the likelihood of transcription on the pre-trained acoustic model and having general characteristics of clean speech, which improve generalization on unseen noisy speeches. We employ the connectionist temporal classification and the unpaired conditional boundary equilibrium generative adversarial network as the loss function of AAS. AAS is tested on two datasets including additive noise without and with reverberation, Librispeech + DEMAND and CHiME-4. By visualizing the enhanced speech with different loss combinations, we demonstrate the role of each supervision. AAS achieves a lower word error rate than other state-of-the-art methods using the clean speech target in both datasets.
PDF Abstract



 LibriSpeech
LibriSpeech
