Unsupervised Object-Level Representation Learning from Scene Images
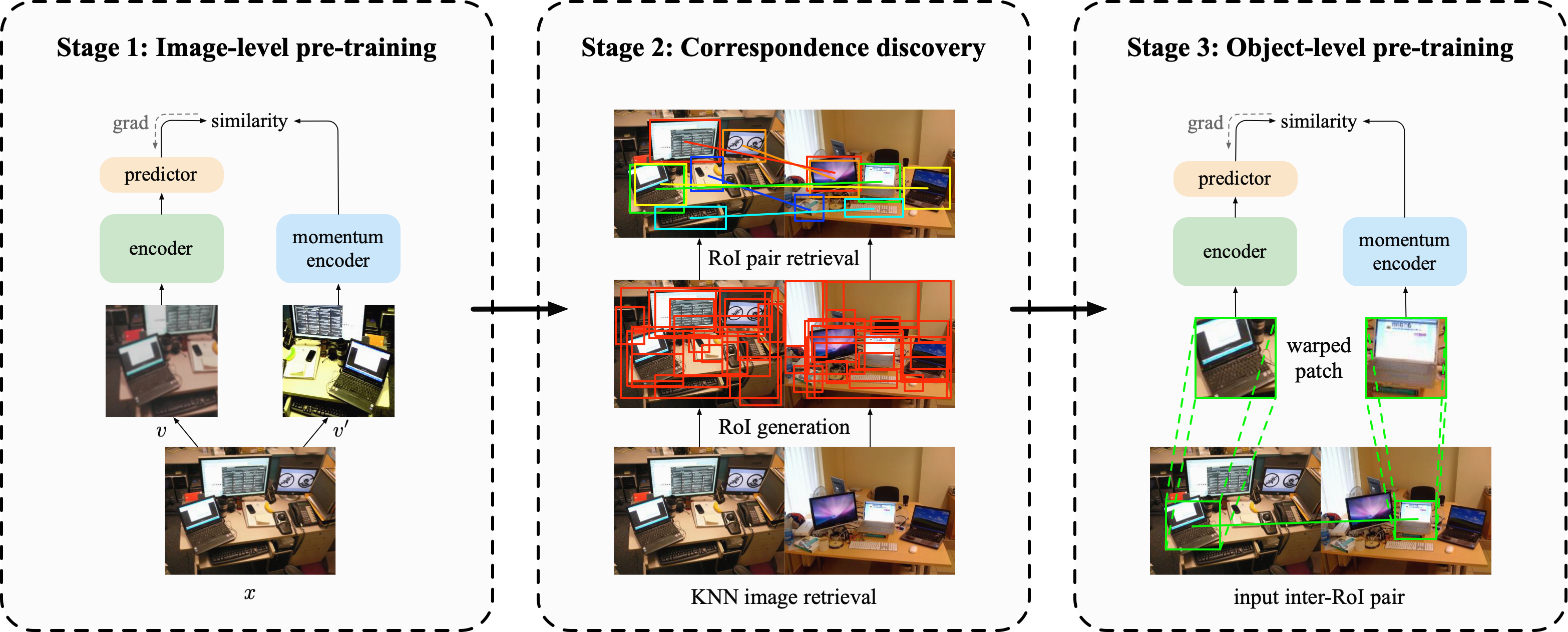
Contrastive self-supervised learning has largely narrowed the gap to supervised pre-training on ImageNet. However, its success highly relies on the object-centric priors of ImageNet, i.e., different augmented views of the same image correspond to the same object. Such a heavily curated constraint becomes immediately infeasible when pre-trained on more complex scene images with many objects. To overcome this limitation, we introduce Object-level Representation Learning (ORL), a new self-supervised learning framework towards scene images. Our key insight is to leverage image-level self-supervised pre-training as the prior to discover object-level semantic correspondence, thus realizing object-level representation learning from scene images. Extensive experiments on COCO show that ORL significantly improves the performance of self-supervised learning on scene images, even surpassing supervised ImageNet pre-training on several downstream tasks. Furthermore, ORL improves the downstream performance when more unlabeled scene images are available, demonstrating its great potential of harnessing unlabeled data in the wild. We hope our approach can motivate future research on more general-purpose unsupervised representation learning from scene data.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract



 ImageNet
ImageNet
 MS COCO
MS COCO
 Places
Places
 Places205
Places205
 iNaturalist
iNaturalist
