Using the Tsetlin Machine to Learn Human-Interpretable Rules for High-Accuracy Text Categorization with Medical Applications
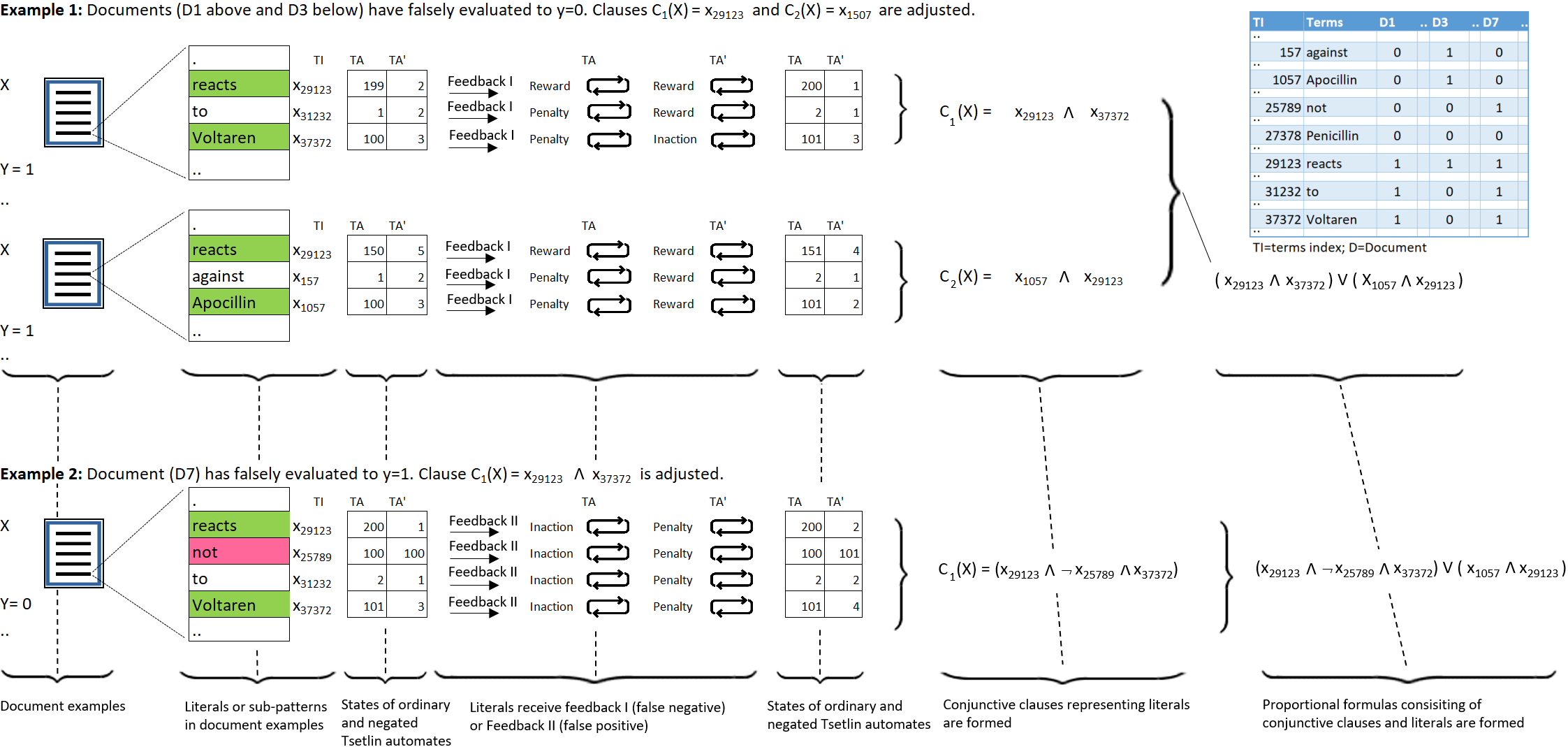
Medical applications challenge today's text categorization techniques by demanding both high accuracy and ease-of-interpretation. Although deep learning has provided a leap ahead in accuracy, this leap comes at the sacrifice of interpretability. To address this accuracy-interpretability challenge, we here introduce, for the first time, a text categorization approach that leverages the recently introduced Tsetlin Machine. In all brevity, we represent the terms of a text as propositional variables. From these, we capture categories using simple propositional formulae, such as: if "rash" and "reaction" and "penicillin" then Allergy. The Tsetlin Machine learns these formulae from a labelled text, utilizing conjunctive clauses to represent the particular facets of each category. Indeed, even the absence of terms (negated features) can be used for categorization purposes. Our empirical comparison with Na\"ive Bayes, decision trees, linear support vector machines (SVMs), random forest, long short-term memory (LSTM) neural networks, and other techniques, is quite conclusive. The Tsetlin Machine either performs on par with or outperforms all of the evaluated methods on both the 20 Newsgroups and IMDb datasets, as well as on a non-public clinical dataset. On average, the Tsetlin Machine delivers the best recall and precision scores across the datasets. Finally, our GPU implementation of the Tsetlin Machine executes 5 to 15 times faster than the CPU implementation, depending on the dataset. We thus believe that our novel approach can have a significant impact on a wide range of text analysis applications, forming a promising starting point for deeper natural language understanding with the Tsetlin Machine.
PDF Abstract

 IMDb Movie Reviews
IMDb Movie Reviews
