Variable-Length Music Score Infilling via XLNet and Musically Specialized Positional Encoding
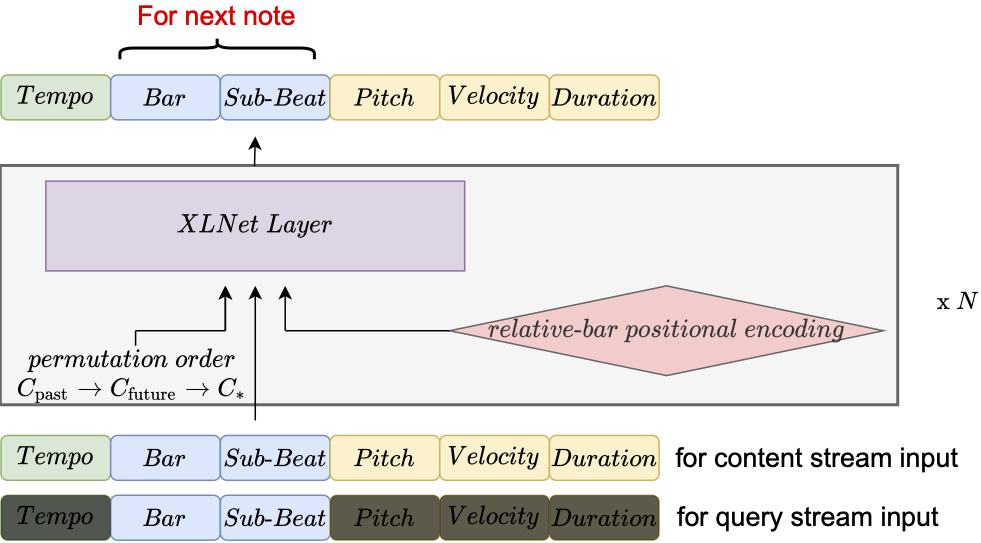
This paper proposes a new self-attention based model for music score infilling, i.e., to generate a polyphonic music sequence that fills in the gap between given past and future contexts. While existing approaches can only fill in a short segment with a fixed number of notes, or a fixed time span between the past and future contexts, our model can infill a variable number of notes (up to 128) for different time spans. We achieve so with three major technical contributions. First, we adapt XLNet, an autoregressive model originally proposed for unsupervised model pre-training, to music score infilling. Second, we propose a new, musically specialized positional encoding called relative bar encoding that better informs the model of notes' position within the past and future context. Third, to capitalize relative bar encoding, we perform look-ahead onset prediction to predict the onset of a note one time step before predicting the other attributes of the note. We compare our proposed model with two strong baselines and show that our model is superior in both objective and subjective analyses.
PDF Abstract
