Vector Quantized Diffusion Model for Text-to-Image Synthesis
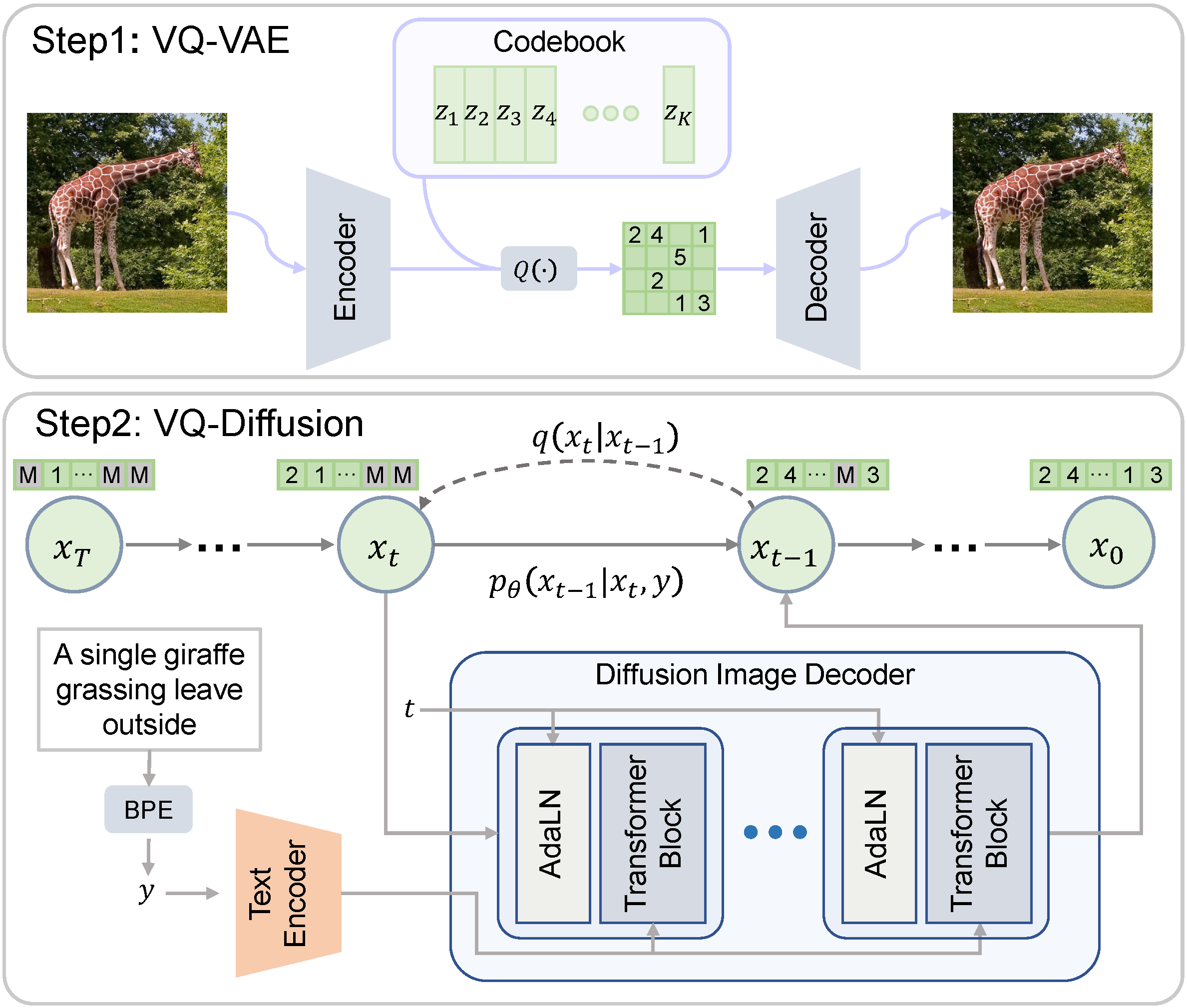
We present the vector quantized diffusion (VQ-Diffusion) model for text-to-image generation. This method is based on a vector quantized variational autoencoder (VQ-VAE) whose latent space is modeled by a conditional variant of the recently developed Denoising Diffusion Probabilistic Model (DDPM). We find that this latent-space method is well-suited for text-to-image generation tasks because it not only eliminates the unidirectional bias with existing methods but also allows us to incorporate a mask-and-replace diffusion strategy to avoid the accumulation of errors, which is a serious problem with existing methods. Our experiments show that the VQ-Diffusion produces significantly better text-to-image generation results when compared with conventional autoregressive (AR) models with similar numbers of parameters. Compared with previous GAN-based text-to-image methods, our VQ-Diffusion can handle more complex scenes and improve the synthesized image quality by a large margin. Finally, we show that the image generation computation in our method can be made highly efficient by reparameterization. With traditional AR methods, the text-to-image generation time increases linearly with the output image resolution and hence is quite time consuming even for normal size images. The VQ-Diffusion allows us to achieve a better trade-off between quality and speed. Our experiments indicate that the VQ-Diffusion model with the reparameterization is fifteen times faster than traditional AR methods while achieving a better image quality.
PDF Abstract CVPR 2022 PDF CVPR 2022 AbstractCode




 ImageNet
ImageNet
 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
 FFHQ
FFHQ
 Oxford 102 Flower
Oxford 102 Flower
 Conceptual Captions
Conceptual Captions
 LAION-400M
LAION-400M
Results from the Paper
 Ranked #1 on
Text-to-Image Generation
on Oxford 102 Flowers
(using extra training data)
Ranked #1 on
Text-to-Image Generation
on Oxford 102 Flowers
(using extra training data)
