Video Corpus Moment Retrieval with Contrastive Learning
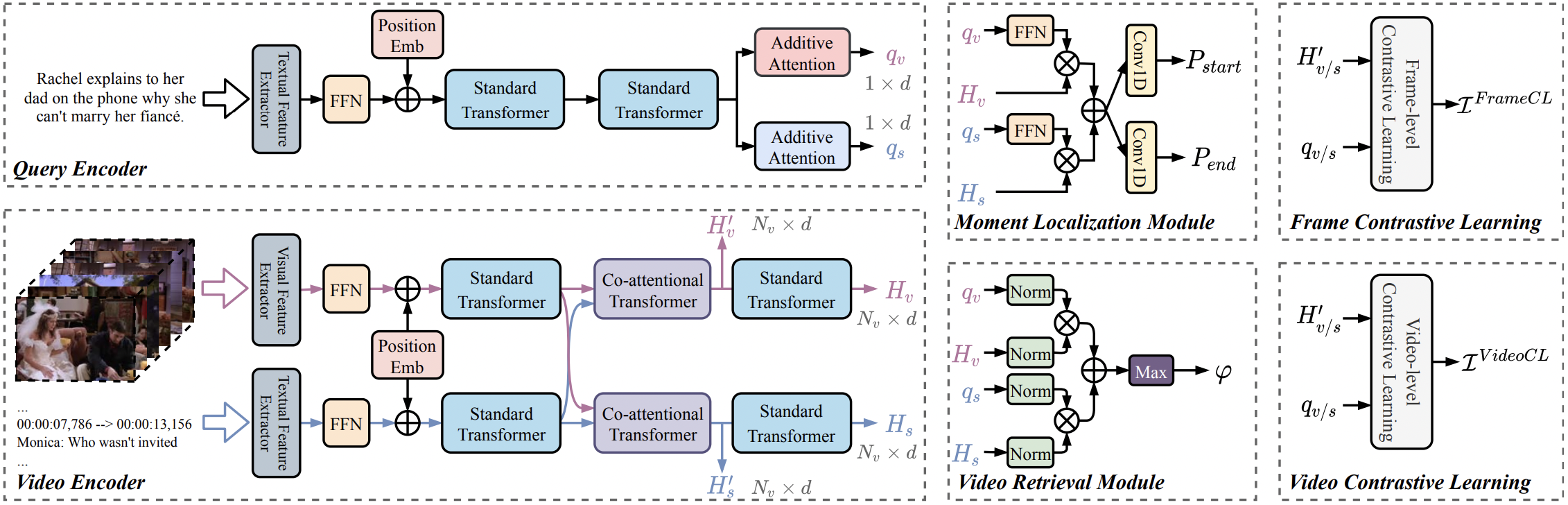
Given a collection of untrimmed and unsegmented videos, video corpus moment retrieval (VCMR) is to retrieve a temporal moment (i.e., a fraction of a video) that semantically corresponds to a given text query. As video and text are from two distinct feature spaces, there are two general approaches to address VCMR: (i) to separately encode each modality representations, then align the two modality representations for query processing, and (ii) to adopt fine-grained cross-modal interaction to learn multi-modal representations for query processing. While the second approach often leads to better retrieval accuracy, the first approach is far more efficient. In this paper, we propose a Retrieval and Localization Network with Contrastive Learning (ReLoCLNet) for VCMR. We adopt the first approach and introduce two contrastive learning objectives to refine video encoder and text encoder to learn video and text representations separately but with better alignment for VCMR. The video contrastive learning (VideoCL) is to maximize mutual information between query and candidate video at video-level. The frame contrastive learning (FrameCL) aims to highlight the moment region corresponds to the query at frame-level, within a video. Experimental results show that, although ReLoCLNet encodes text and video separately for efficiency, its retrieval accuracy is comparable with baselines adopting cross-modal interaction learning.
PDF Abstract



 ActivityNet Captions
ActivityNet Captions
