Video Playback Rate Perception for Self-supervisedSpatio-Temporal Representation Learning
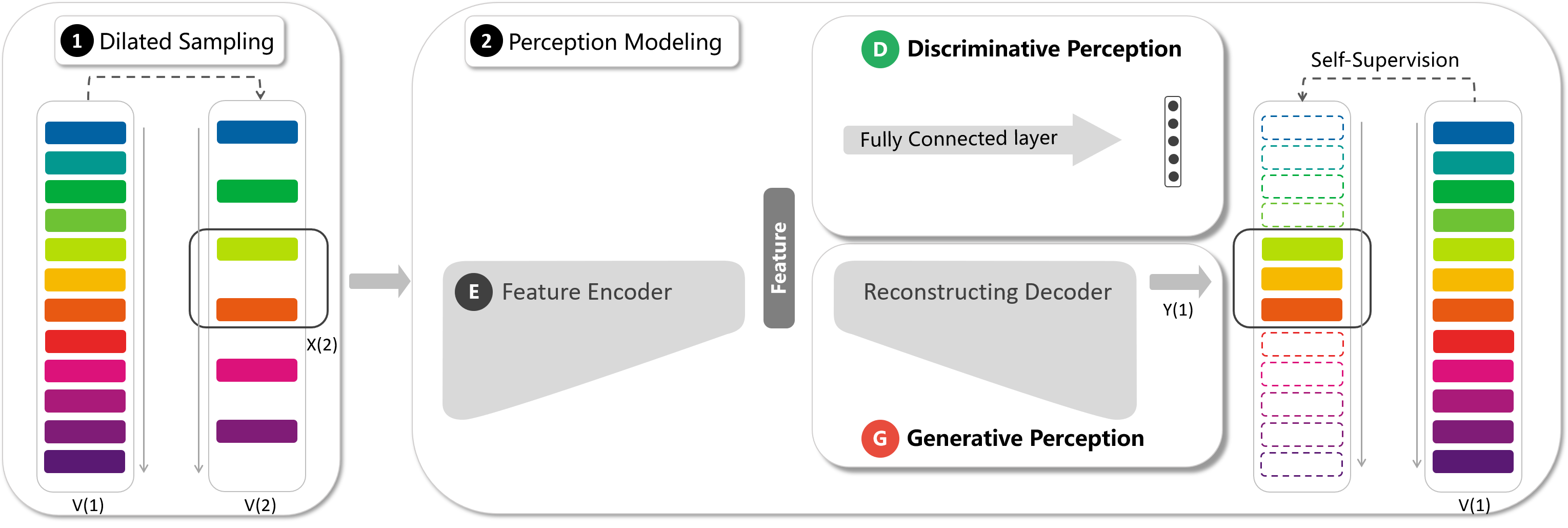
In self-supervised spatio-temporal representation learning, the temporal resolution and long-short term characteristics are not yet fully explored, which limits representation capabilities of learned models. In this paper, we propose a novel self-supervised method, referred to as video Playback Rate Perception (PRP), to learn spatio-temporal representation in a simple-yet-effective way. PRP roots in a dilated sampling strategy, which produces self-supervision signals about video playback rates for representation model learning. PRP is implemented with a feature encoder, a classification module, and a reconstructing decoder, to achieve spatio-temporal semantic retention in a collaborative discrimination-generation manner. The discriminative perception model follows a feature encoder to prefer perceiving low temporal resolution and long-term representation by classifying fast-forward rates. The generative perception model acts as a feature decoder to focus on comprehending high temporal resolution and short-term representation by introducing a motion-attention mechanism. PRP is applied on typical video target tasks including action recognition and video retrieval. Experiments show that PRP outperforms state-of-the-art self-supervised models with significant margins. Code is available at github.com/yuanyao366/PRP
PDF Abstract



 ImageNet
ImageNet
 UCF101
UCF101
 HMDB51
HMDB51
