Video2Commonsense: Generating Commonsense Descriptions to Enrich Video Captioning
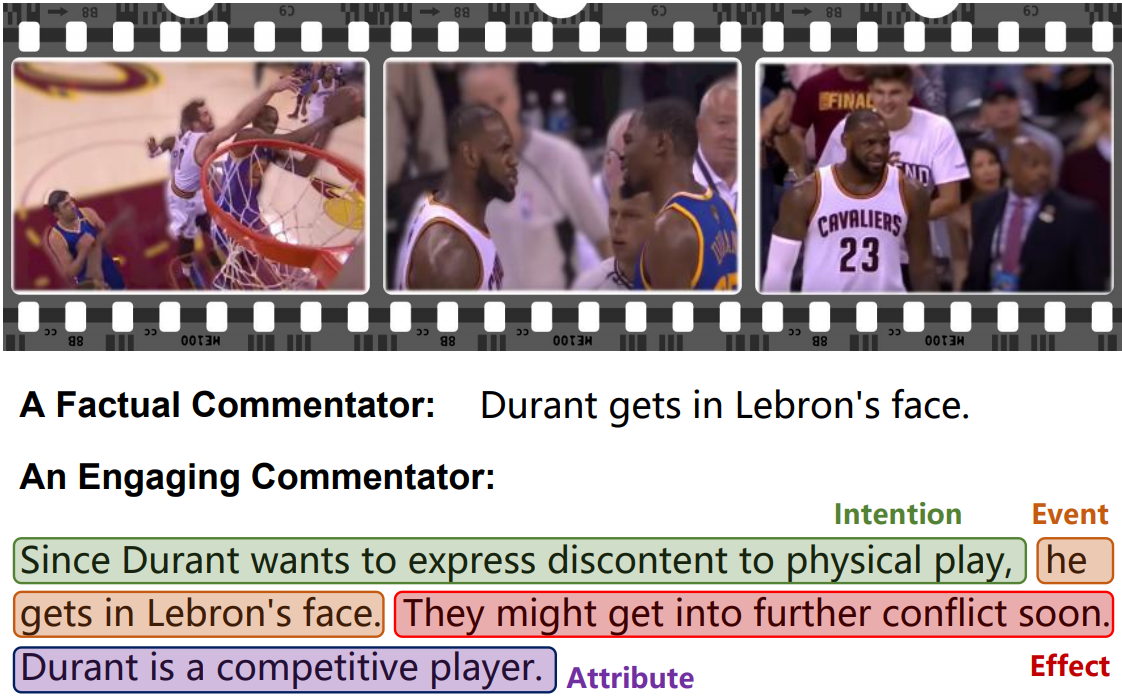
Captioning is a crucial and challenging task for video understanding. In videos that involve active agents such as humans, the agent's actions can bring about myriad changes in the scene. Observable changes such as movements, manipulations, and transformations of the objects in the scene, are reflected in conventional video captioning. Unlike images, actions in videos are also inherently linked to social aspects such as intentions (why the action is taking place), effects (what changes due to the action), and attributes that describe the agent. Thus for video understanding, such as when captioning videos or when answering questions about videos, one must have an understanding of these commonsense aspects. We present the first work on generating commonsense captions directly from videos, to describe latent aspects such as intentions, effects, and attributes. We present a new dataset "Video-to-Commonsense (V2C)" that contains $\sim9k$ videos of human agents performing various actions, annotated with 3 types of commonsense descriptions. Additionally we explore the use of open-ended video-based commonsense question answering (V2C-QA) as a way to enrich our captions. Both the generation task and the QA task can be used to enrich video captions.
PDF Abstract EMNLP 2020 PDF EMNLP 2020 Abstract


Datasets
Introduced in the Paper:
V2C