VIMI: Vehicle-Infrastructure Multi-view Intermediate Fusion for Camera-based 3D Object Detection
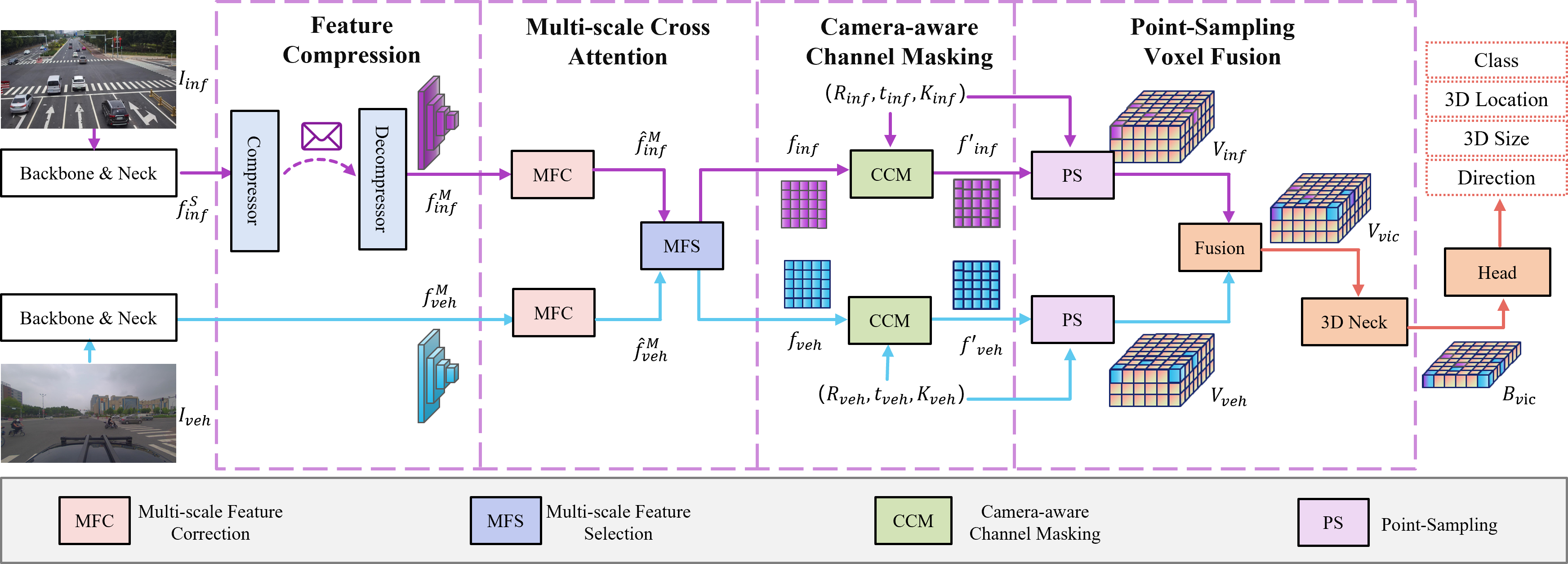
In autonomous driving, Vehicle-Infrastructure Cooperative 3D Object Detection (VIC3D) makes use of multi-view cameras from both vehicles and traffic infrastructure, providing a global vantage point with rich semantic context of road conditions beyond a single vehicle viewpoint. Two major challenges prevail in VIC3D: 1) inherent calibration noise when fusing multi-view images, caused by time asynchrony across cameras; 2) information loss when projecting 2D features into 3D space. To address these issues, We propose a novel 3D object detection framework, Vehicles-Infrastructure Multi-view Intermediate fusion (VIMI). First, to fully exploit the holistic perspectives from both vehicles and infrastructure, we propose a Multi-scale Cross Attention (MCA) module that fuses infrastructure and vehicle features on selective multi-scales to correct the calibration noise introduced by camera asynchrony. Then, we design a Camera-aware Channel Masking (CCM) module that uses camera parameters as priors to augment the fused features. We further introduce a Feature Compression (FC) module with channel and spatial compression blocks to reduce the size of transmitted features for enhanced efficiency. Experiments show that VIMI achieves 15.61% overall AP_3D and 21.44% AP_BEV on the new VIC3D dataset, DAIR-V2X-C, significantly outperforming state-of-the-art early fusion and late fusion methods with comparable transmission cost.
PDF Abstract




 nuScenes
nuScenes
 OPV2V
OPV2V
 V2X-SIM
V2X-SIM
