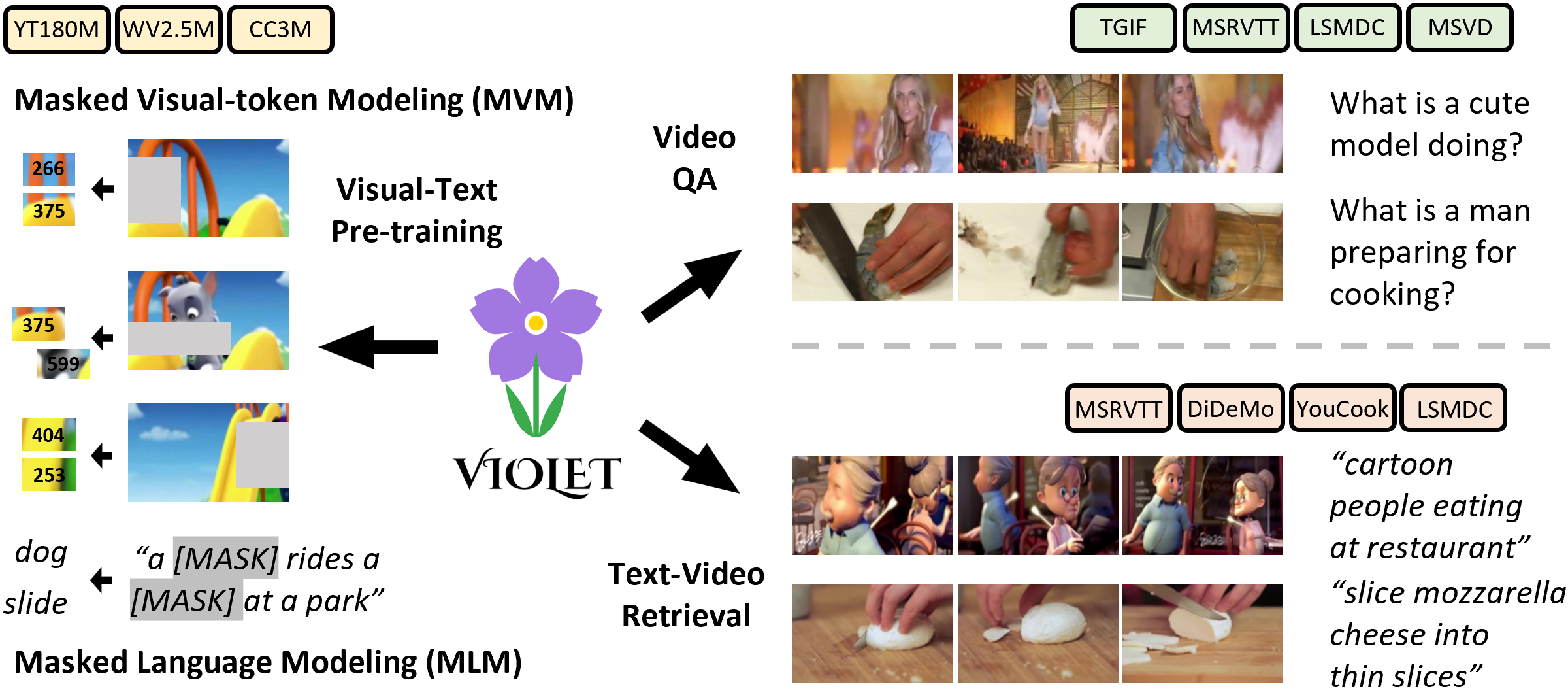
VIOLET : End-to-End Video-Language Transformers with Masked Visual-token Modeling
A great challenge in video-language (VidL) modeling lies in the disconnection between fixed video representations extracted from image/video understanding models and downstream VidL data. Recent studies try to mitigate this disconnection via end-to-end training. To make it computationally feasible, prior works tend to "imagify" video inputs, i.e., a handful of sparsely sampled frames are fed into a 2D CNN, followed by a simple mean-pooling or concatenation to obtain the overall video representations. Although achieving promising results, such simple approaches may lose temporal information that is essential for performing downstream VidL tasks. In this work, we present VIOLET, a fully end-to-end VIdeO-LanguagE Transformer, which adopts a video transformer to explicitly model the temporal dynamics of video inputs. Further, unlike previous studies that found pre-training tasks on video inputs (e.g., masked frame modeling) not very effective, we design a new pre-training task, Masked Visual-token Modeling (MVM), for better video modeling. Specifically, the original video frame patches are "tokenized" into discrete visual tokens, and the goal is to recover the original visual tokens based on the masked patches. Comprehensive analysis demonstrates the effectiveness of both explicit temporal modeling via video transformer and MVM. As a result, VIOLET achieves new state-of-the-art performance on 5 video question answering tasks and 4 text-to-video retrieval tasks.
PDF Abstract


 ImageNet
ImageNet
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 DiDeMo
DiDeMo
 WebVid
WebVid
 YouCook2
YouCook2
 VCR
VCR
 LSMDC
LSMDC

