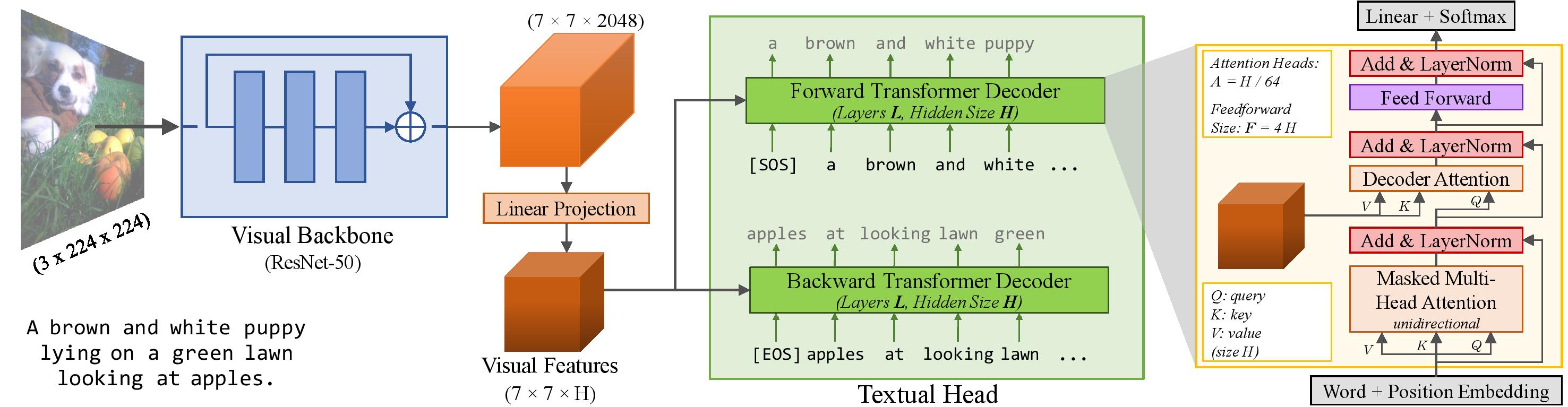
VirTex: Learning Visual Representations from Textual Annotations
The de-facto approach to many vision tasks is to start from pretrained visual representations, typically learned via supervised training on ImageNet. Recent methods have explored unsupervised pretraining to scale to vast quantities of unlabeled images. In contrast, we aim to learn high-quality visual representations from fewer images. To this end, we revisit supervised pretraining, and seek data-efficient alternatives to classification-based pretraining. We propose VirTex -- a pretraining approach using semantically dense captions to learn visual representations. We train convolutional networks from scratch on COCO Captions, and transfer them to downstream recognition tasks including image classification, object detection, and instance segmentation. On all tasks, VirTex yields features that match or exceed those learned on ImageNet -- supervised or unsupervised -- despite using up to ten times fewer images.
PDF Abstract CVPR 2021 PDF CVPR 2021 Abstract







 ImageNet
ImageNet
 MS COCO
MS COCO
 Visual Genome
Visual Genome
 iNaturalist
iNaturalist
 LVIS
LVIS
 COCO Captions
COCO Captions
Results from the Paper
 Ranked #1 on
Object Detection
on COCO test-dev
(Hardware Burden metric)
Ranked #1 on
Object Detection
on COCO test-dev
(Hardware Burden metric)
