Vision Transformer with Quadrangle Attention
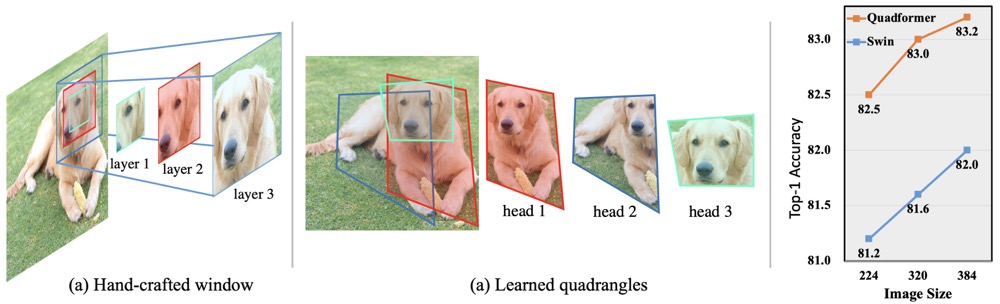
Window-based attention has become a popular choice in vision transformers due to its superior performance, lower computational complexity, and less memory footprint. However, the design of hand-crafted windows, which is data-agnostic, constrains the flexibility of transformers to adapt to objects of varying sizes, shapes, and orientations. To address this issue, we propose a novel quadrangle attention (QA) method that extends the window-based attention to a general quadrangle formulation. Our method employs an end-to-end learnable quadrangle regression module that predicts a transformation matrix to transform default windows into target quadrangles for token sampling and attention calculation, enabling the network to model various targets with different shapes and orientations and capture rich context information. We integrate QA into plain and hierarchical vision transformers to create a new architecture named QFormer, which offers minor code modifications and negligible extra computational cost. Extensive experiments on public benchmarks demonstrate that QFormer outperforms existing representative vision transformers on various vision tasks, including classification, object detection, semantic segmentation, and pose estimation. The code will be made publicly available at \href{https://github.com/ViTAE-Transformer/QFormer}{QFormer}.
PDF Abstract




 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K
