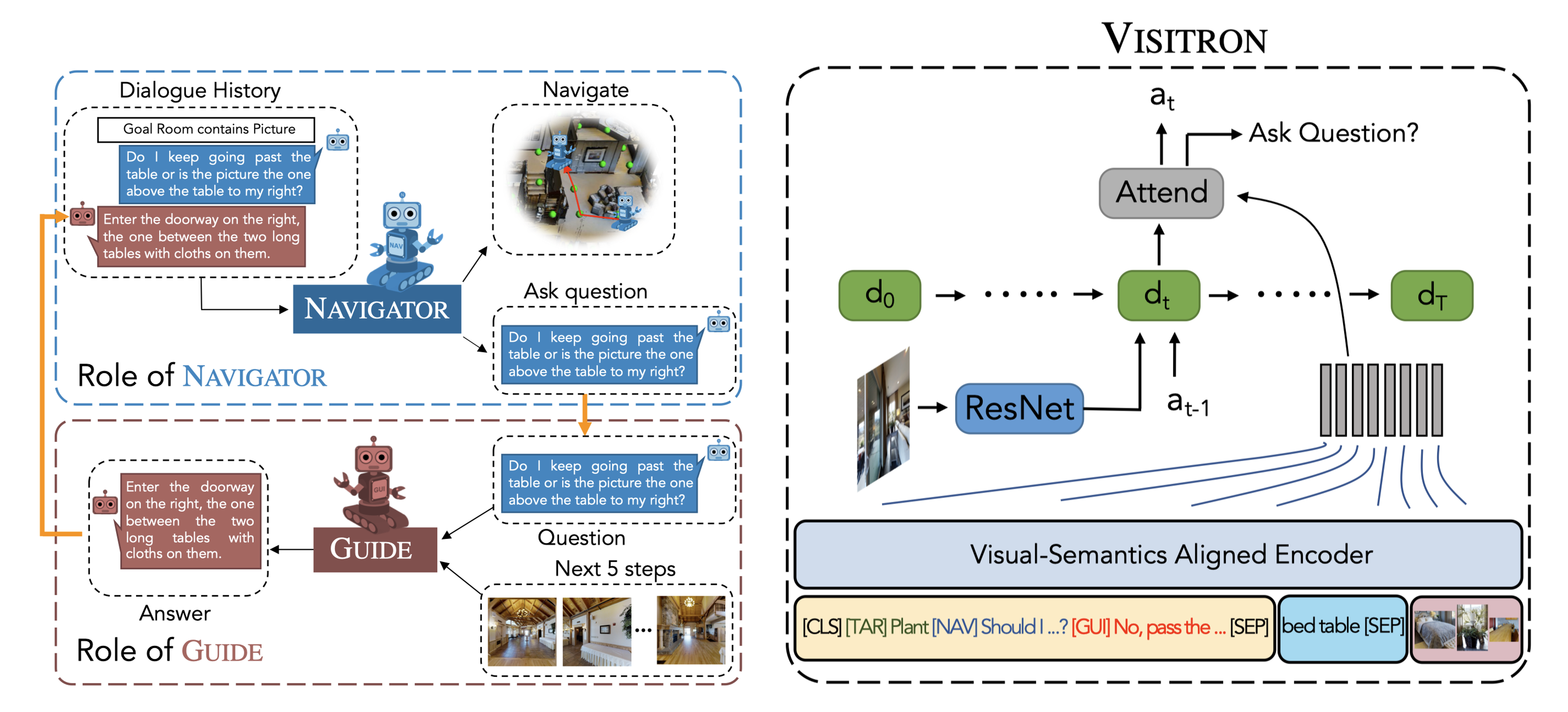
VISITRON: Visual Semantics-Aligned Interactively Trained Object-Navigator
Interactive robots navigating photo-realistic environments need to be trained to effectively leverage and handle the dynamic nature of dialogue in addition to the challenges underlying vision-and-language navigation (VLN). In this paper, we present VISITRON, a multi-modal Transformer-based navigator better suited to the interactive regime inherent to Cooperative Vision-and-Dialog Navigation (CVDN). VISITRON is trained to: i) identify and associate object-level concepts and semantics between the environment and dialogue history, ii) identify when to interact vs. navigate via imitation learning of a binary classification head. We perform extensive pre-training and fine-tuning ablations with VISITRON to gain empirical insights and improve performance on CVDN. VISITRON's ability to identify when to interact leads to a natural generalization of the game-play mode introduced by Roman et al. (arXiv:2005.00728) for enabling the use of such models in different environments. VISITRON is competitive with models on the static CVDN leaderboard and attains state-of-the-art performance on the Success weighted by Path Length (SPL) metric.
PDF Abstract Findings (ACL) 2022 PDF Findings (ACL) 2022 Abstract

 Matterport3D
Matterport3D
 RxR
RxR
