Cross-Modal Causal Intervention for Medical Report Generation
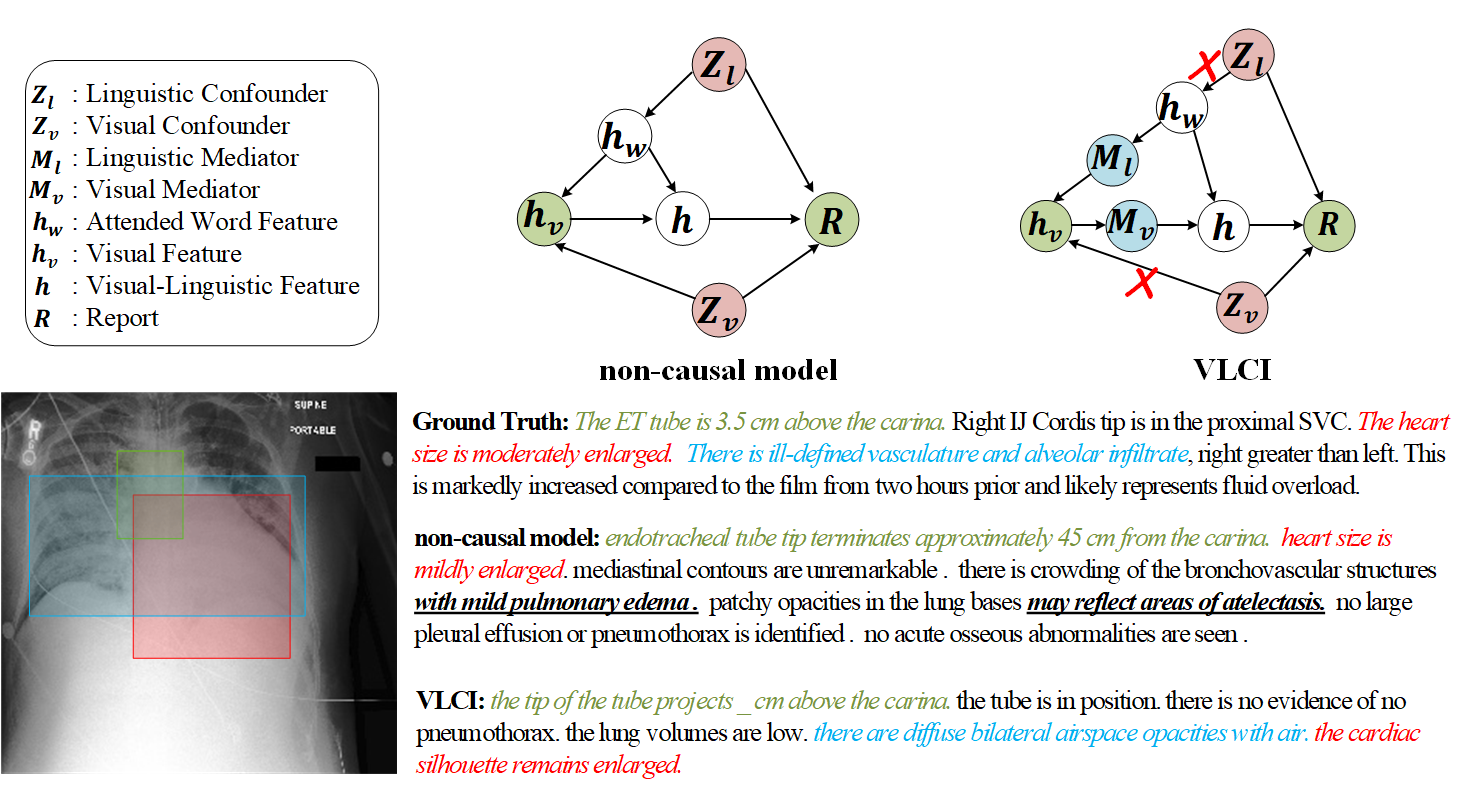
Medical report generation (MRG) is essential for computer-aided diagnosis and medication guidance, which can relieve the heavy burden of radiologists by automatically generating the corresponding medical reports according to the given radiology image. However, due to the spurious correlations within image-text data induced by visual and linguistic biases, it is challenging to generate accurate reports reliably describing lesion areas. Moreover, the cross-modal confounders are usually unobservable and challenging to be eliminated explicitly. In this paper, we aim to mitigate the cross-modal data bias for MRG from a new perspective, i.e., cross-modal causal intervention, and propose a novel Visual-Linguistic Causal Intervention (VLCI) framework for MRG, which consists of a visual deconfounding module (VDM) and a linguistic deconfounding module (LDM), to implicitly mitigate the visual-linguistic confounders by causal front-door intervention. Specifically, due to the absence of a generalized semantic extractor, the VDM explores and disentangles the visual confounders from the patch-based local and global features without expensive fine-grained annotations. Simultaneously, due to the lack of knowledge encompassing the entire field of medicine, the LDM eliminates the linguistic confounders caused by salient visual features and high-frequency context without constructing a terminology database. Extensive experiments on IU-Xray and MIMIC-CXR datasets show that our VLCI significantly outperforms the state-of-the-art MRG methods. The code and models are available at https://github.com/WissingChen/VLCI.
PDF Abstract



 CheXpert
CheXpert
 MIMIC-CXR
MIMIC-CXR
