ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers
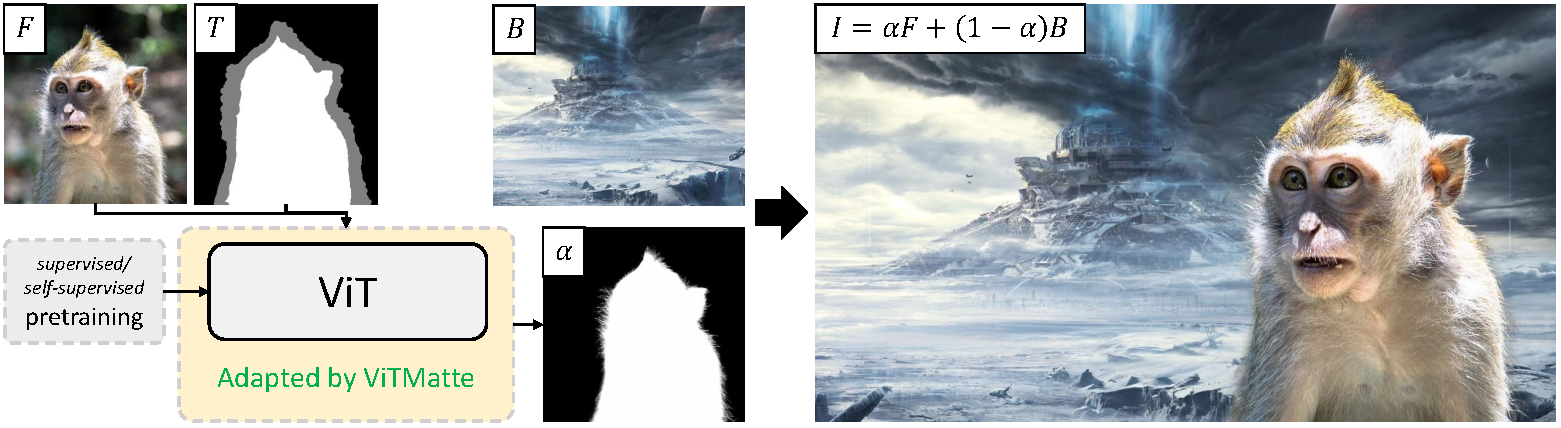
Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.
PDF Abstract Colab
Colab



 ImageNet
ImageNet
 Composition-1K
Composition-1K

