VLTinT: Visual-Linguistic Transformer-in-Transformer for Coherent Video Paragraph Captioning
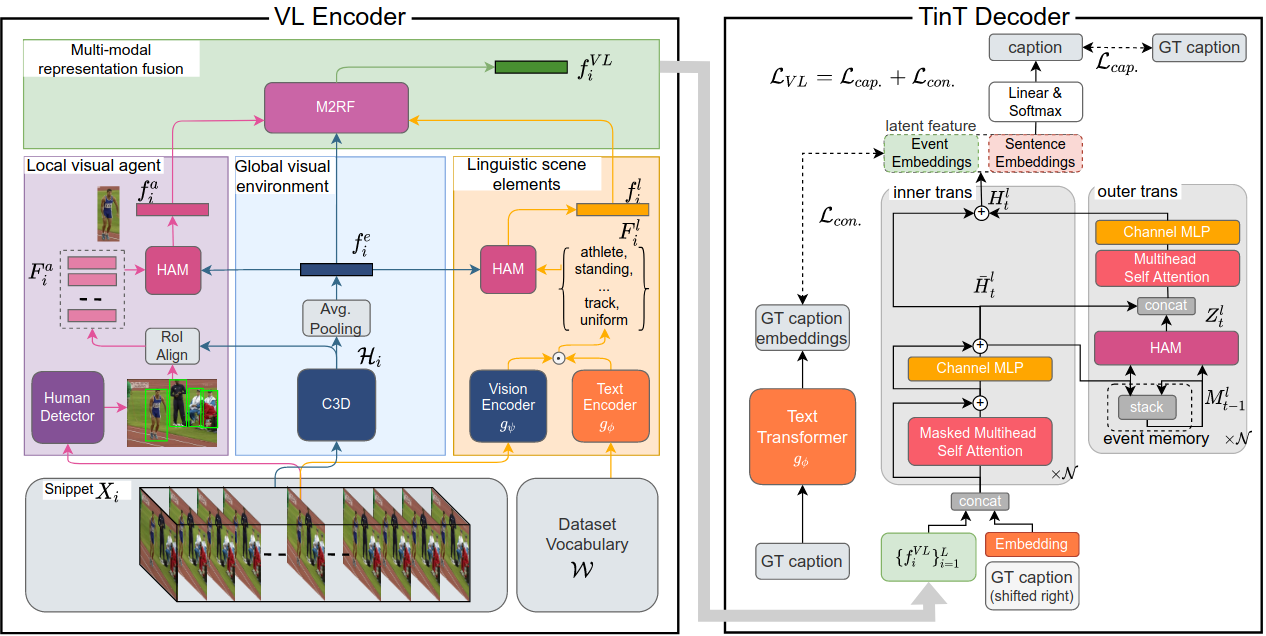
Video paragraph captioning aims to generate a multi-sentence description of an untrimmed video with several temporal event locations in coherent storytelling. Following the human perception process, where the scene is effectively understood by decomposing it into visual (e.g. human, animal) and non-visual components (e.g. action, relations) under the mutual influence of vision and language, we first propose a visual-linguistic (VL) feature. In the proposed VL feature, the scene is modeled by three modalities including (i) a global visual environment; (ii) local visual main agents; (iii) linguistic scene elements. We then introduce an autoregressive Transformer-in-Transformer (TinT) to simultaneously capture the semantic coherence of intra- and inter-event contents within a video. Finally, we present a new VL contrastive loss function to guarantee learnt embedding features are matched with the captions semantics. Comprehensive experiments and extensive ablation studies on ActivityNet Captions and YouCookII datasets show that the proposed Visual-Linguistic Transformer-in-Transform (VLTinT) outperforms prior state-of-the-art methods on accuracy and diversity. Source code is made publicly available at: https://github.com/UARK-AICV/VLTinT.
PDF Abstract

 ActivityNet Captions
ActivityNet Captions

