vMFNet: Compositionality Meets Domain-generalised Segmentation
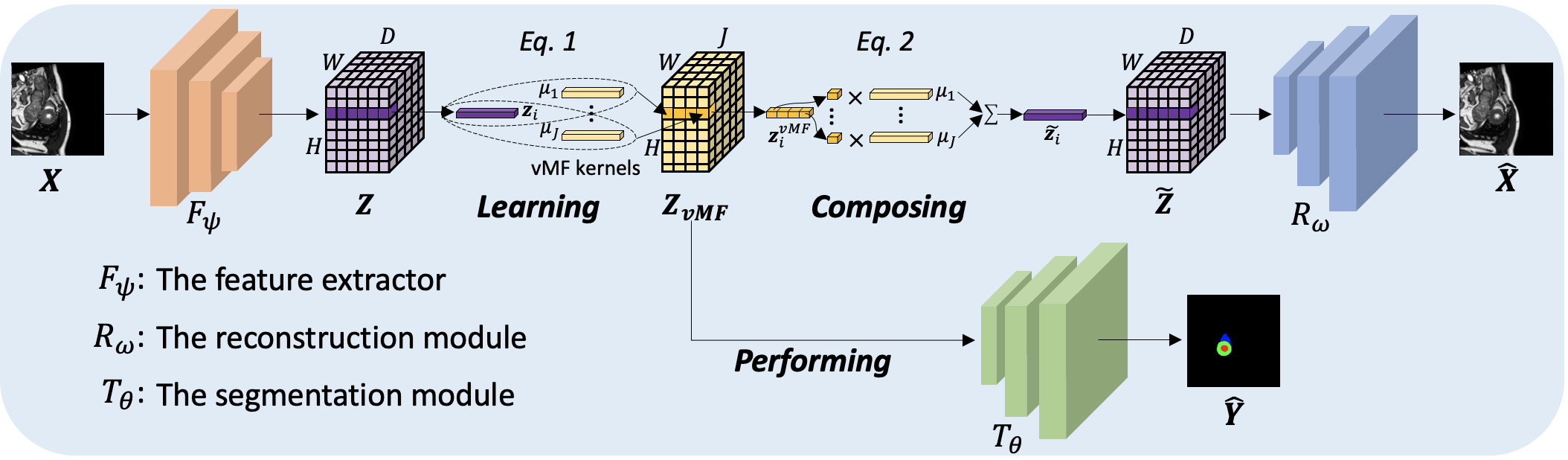
Training medical image segmentation models usually requires a large amount of labeled data. By contrast, humans can quickly learn to accurately recognise anatomy of interest from medical (e.g. MRI and CT) images with some limited guidance. Such recognition ability can easily generalise to new images from different clinical centres. This rapid and generalisable learning ability is mostly due to the compositional structure of image patterns in the human brain, which is less incorporated in medical image segmentation. In this paper, we model the compositional components (i.e. patterns) of human anatomy as learnable von-Mises-Fisher (vMF) kernels, which are robust to images collected from different domains (e.g. clinical centres). The image features can be decomposed to (or composed by) the components with the composing operations, i.e. the vMF likelihoods. The vMF likelihoods tell how likely each anatomical part is at each position of the image. Hence, the segmentation mask can be predicted based on the vMF likelihoods. Moreover, with a reconstruction module, unlabeled data can also be used to learn the vMF kernels and likelihoods by recombining them to reconstruct the input image. Extensive experiments show that the proposed vMFNet achieves improved generalisation performance on two benchmarks, especially when annotations are limited. Code is publicly available at: https://github.com/vios-s/vMFNet.
PDF Abstract



