Voice activity detection in the wild via weakly supervised sound event detection
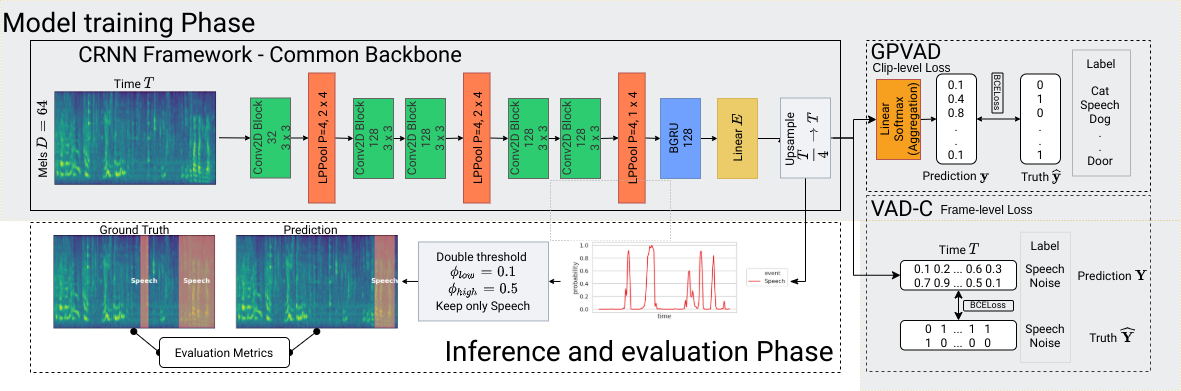
Traditional supervised voice activity detection (VAD) methods work well in clean and controlled scenarios, with performance severely degrading in real-world applications. One possible bottleneck is that speech in the wild contains unpredictable noise types, hence frame-level label prediction is difficult, which is required for traditional supervised VAD training. In contrast, we propose a general-purpose VAD (GPVAD) framework, which can be easily trained from noisy data in a weakly supervised fashion, requiring only clip-level labels. We proposed two GPVAD models, one full (GPV-F), trained on 527 Audioset sound events, and one binary (GPV-B), only distinguishing speech and noise. We evaluate the two GPV models against a CRNN based standard VAD model (VAD-C) on three different evaluation protocols (clean, synthetic noise, real data). Results show that our proposed GPV-F demonstrates competitive performance in clean and synthetic scenarios compared to traditional VAD-C. Further, in real-world evaluation, GPV-F largely outperforms VAD-C in terms of frame-level evaluation metrics as well as segment-level ones. With a much lower requirement for frame-labeled data, the naive binary clip-level GPV-B model can still achieve comparable performance to VAD-C in real-world scenarios.
PDF Abstract
 AudioSet
AudioSet
