Voice Conversion from Non-parallel Corpora Using Variational Auto-encoder
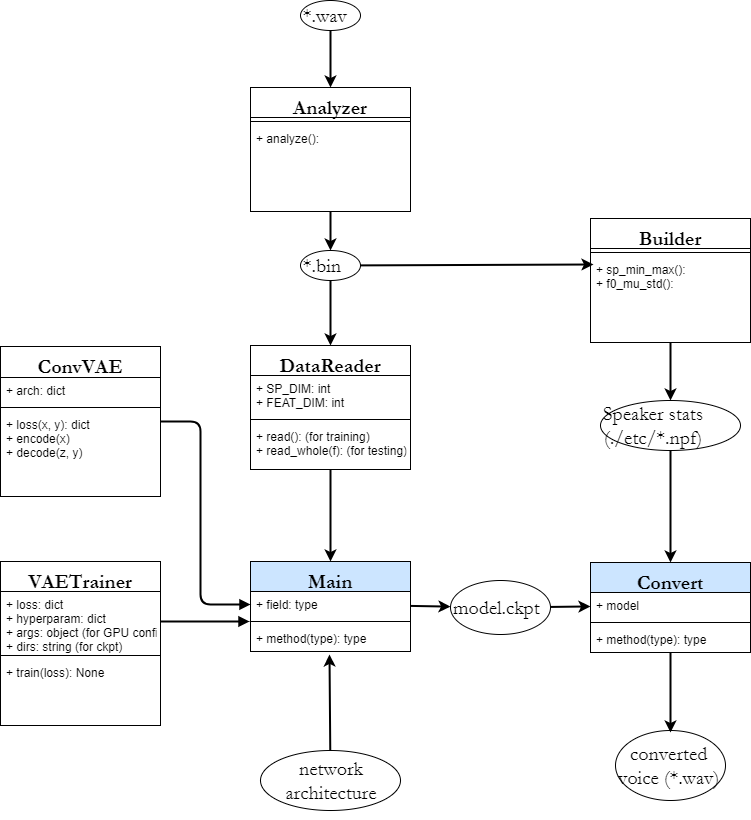
We propose a flexible framework for spectral conversion (SC) that facilitates training with unaligned corpora. Many SC frameworks require parallel corpora, phonetic alignments, or explicit frame-wise correspondence for learning conversion functions or for synthesizing a target spectrum with the aid of alignments. However, these requirements gravely limit the scope of practical applications of SC due to scarcity or even unavailability of parallel corpora. We propose an SC framework based on variational auto-encoder which enables us to exploit non-parallel corpora. The framework comprises an encoder that learns speaker-independent phonetic representations and a decoder that learns to reconstruct the designated speaker. It removes the requirement of parallel corpora or phonetic alignments to train a spectral conversion system. We report objective and subjective evaluations to validate our proposed method and compare it to SC methods that have access to aligned corpora.
PDF Abstract


