Voice2Series: Reprogramming Acoustic Models for Time Series Classification
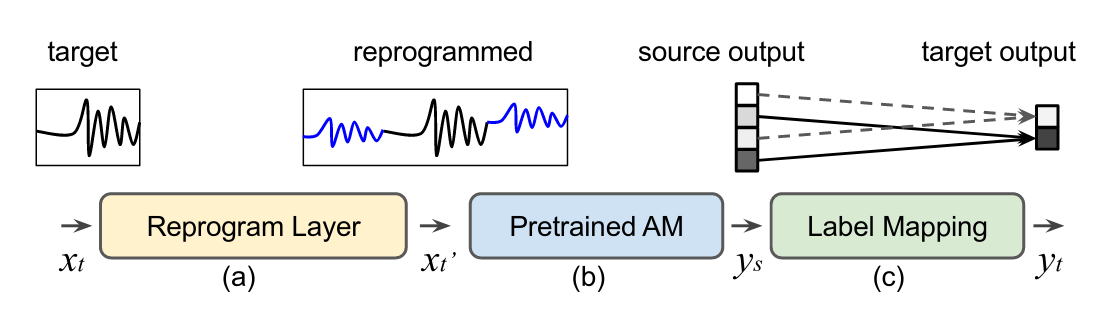
Learning to classify time series with limited data is a practical yet challenging problem. Current methods are primarily based on hand-designed feature extraction rules or domain-specific data augmentation. Motivated by the advances in deep speech processing models and the fact that voice data are univariate temporal signals, in this paper, we propose Voice2Series (V2S), a novel end-to-end approach that reprograms acoustic models for time series classification, through input transformation learning and output label mapping. Leveraging the representation learning power of a large-scale pre-trained speech processing model, on 30 different time series tasks we show that V2S performs competitive results on 19 time series classification tasks. We further provide a theoretical justification of V2S by proving its population risk is upper bounded by the source risk and a Wasserstein distance accounting for feature alignment via reprogramming. Our results offer new and effective means to time series classification.
PDF Abstract Colab
Colab







 AudioSet
AudioSet

