Stronger NAS with Weaker Predictors
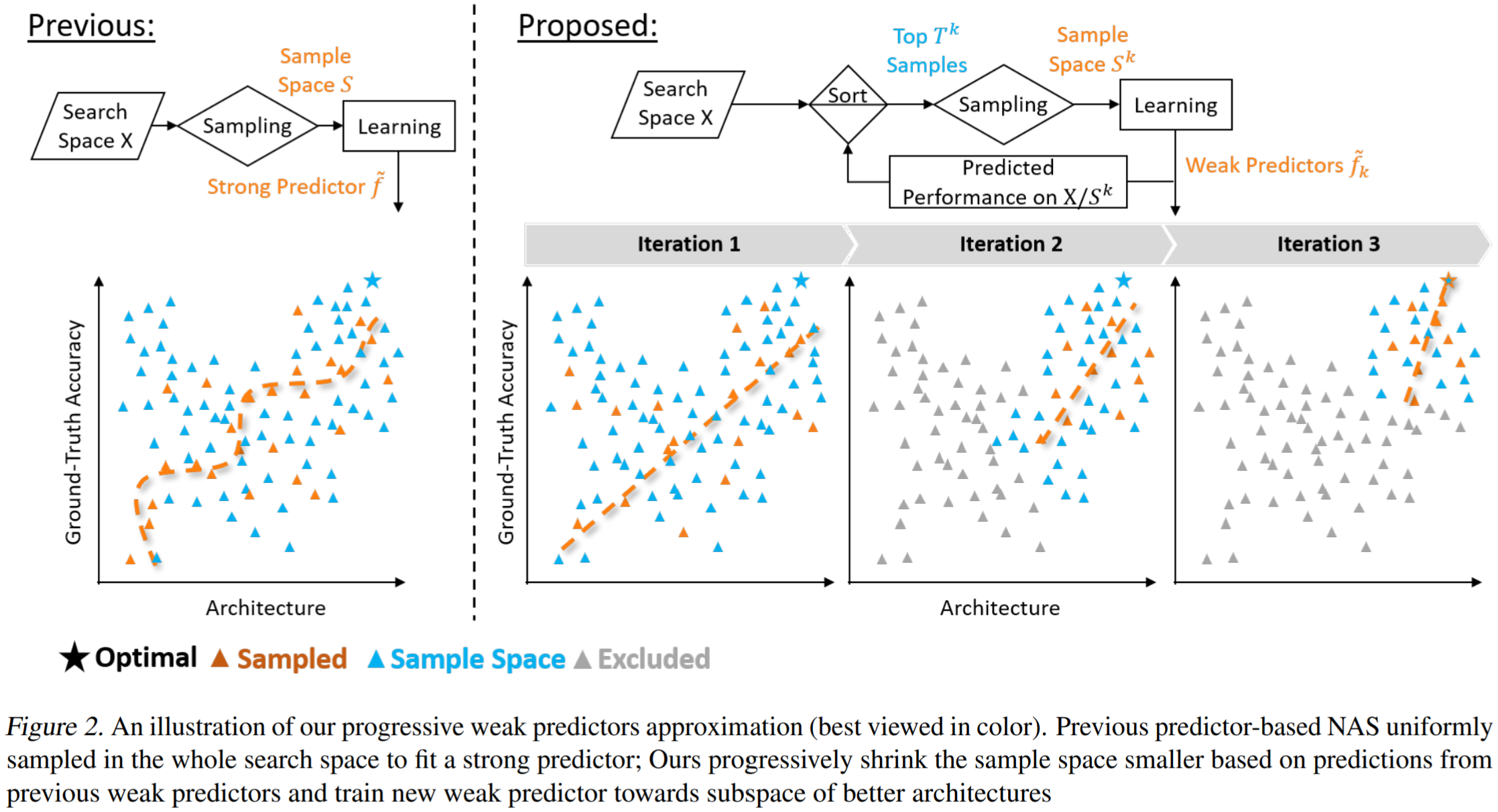
Neural Architecture Search (NAS) often trains and evaluates a large number of architectures. Recent predictor-based NAS approaches attempt to alleviate such heavy computation costs with two key steps: sampling some architecture-performance pairs and fitting a proxy accuracy predictor. Given limited samples, these predictors, however, are far from accurate to locate top architectures due to the difficulty of fitting the huge search space. This paper reflects on a simple yet crucial question: if our final goal is to find the best architecture, do we really need to model the whole space well?. We propose a paradigm shift from fitting the whole architecture space using one strong predictor, to progressively fitting a search path towards the high-performance sub-space through a set of weaker predictors. As a key property of the weak predictors, their probabilities of sampling better architectures keep increasing. Hence we only sample a few well-performed architectures guided by the previously learned predictor and estimate a new better weak predictor. This embarrassingly easy framework, dubbed WeakNAS, produces coarse-to-fine iteration to gradually refine the ranking of sampling space. Extensive experiments demonstrate that WeakNAS costs fewer samples to find top-performance architectures on NAS-Bench-101 and NAS-Bench-201. Compared to state-of-the-art (SOTA) predictor-based NAS methods, WeakNAS outperforms all with notable margins, e.g., requiring at least 7.5x less samples to find global optimal on NAS-Bench-101. WeakNAS can also absorb their ideas to boost performance more. Further, WeakNAS strikes the new SOTA result of 81.3% in the ImageNet MobileNet Search Space. The code is available at https://github.com/VITA-Group/WeakNAS.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract

 CIFAR-10
CIFAR-10
 CIFAR-100
CIFAR-100
 NAS-Bench-201
NAS-Bench-201
 NAS-Bench-101
NAS-Bench-101
