Weakly Supervised 3D Object Detection from Lidar Point Cloud
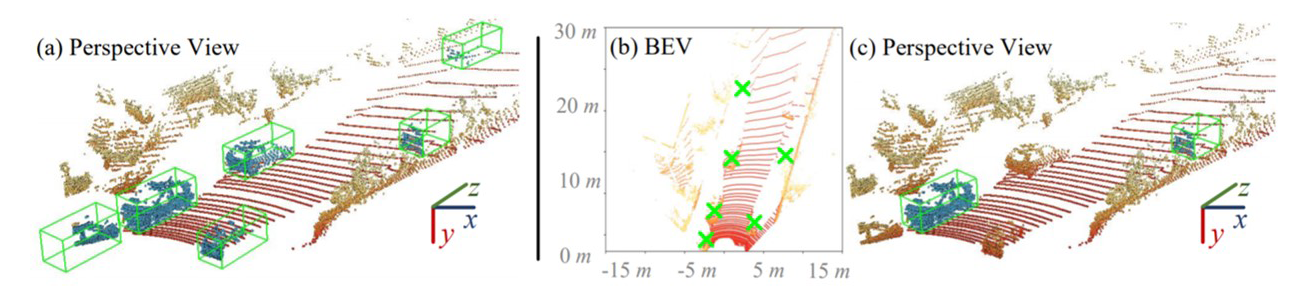
It is laborious to manually label point cloud data for training high-quality 3D object detectors. This work proposes a weakly supervised approach for 3D object detection, only requiring a small set of weakly annotated scenes, associated with a few precisely labeled object instances. This is achieved by a two-stage architecture design. Stage-1 learns to generate cylindrical object proposals under weak supervision, i.e., only the horizontal centers of objects are click-annotated on bird's view scenes. Stage-2 learns to refine the cylindrical proposals to get cuboids and confidence scores, using a few well-labeled object instances. Using only 500 weakly annotated scenes and 534 precisely labeled vehicle instances, our method achieves 85-95% the performance of current top-leading, fully supervised detectors (which require 3, 712 exhaustively and precisely annotated scenes with 15, 654 instances). More importantly, with our elaborately designed network architecture, our trained model can be applied as a 3D object annotator, allowing both automatic and active working modes. The annotations generated by our model can be used to train 3D object detectors with over 94% of their original performance (under manually labeled data). Our experiments also show our model's potential in boosting performance given more training data. Above designs make our approach highly practical and introduce new opportunities for learning 3D object detection with reduced annotation burden.
PDF Abstract ECCV 2020 PDF ECCV 2020 Abstract



 KITTI
KITTI
