Weakly supervised segmentation with cross-modality equivariant constraints
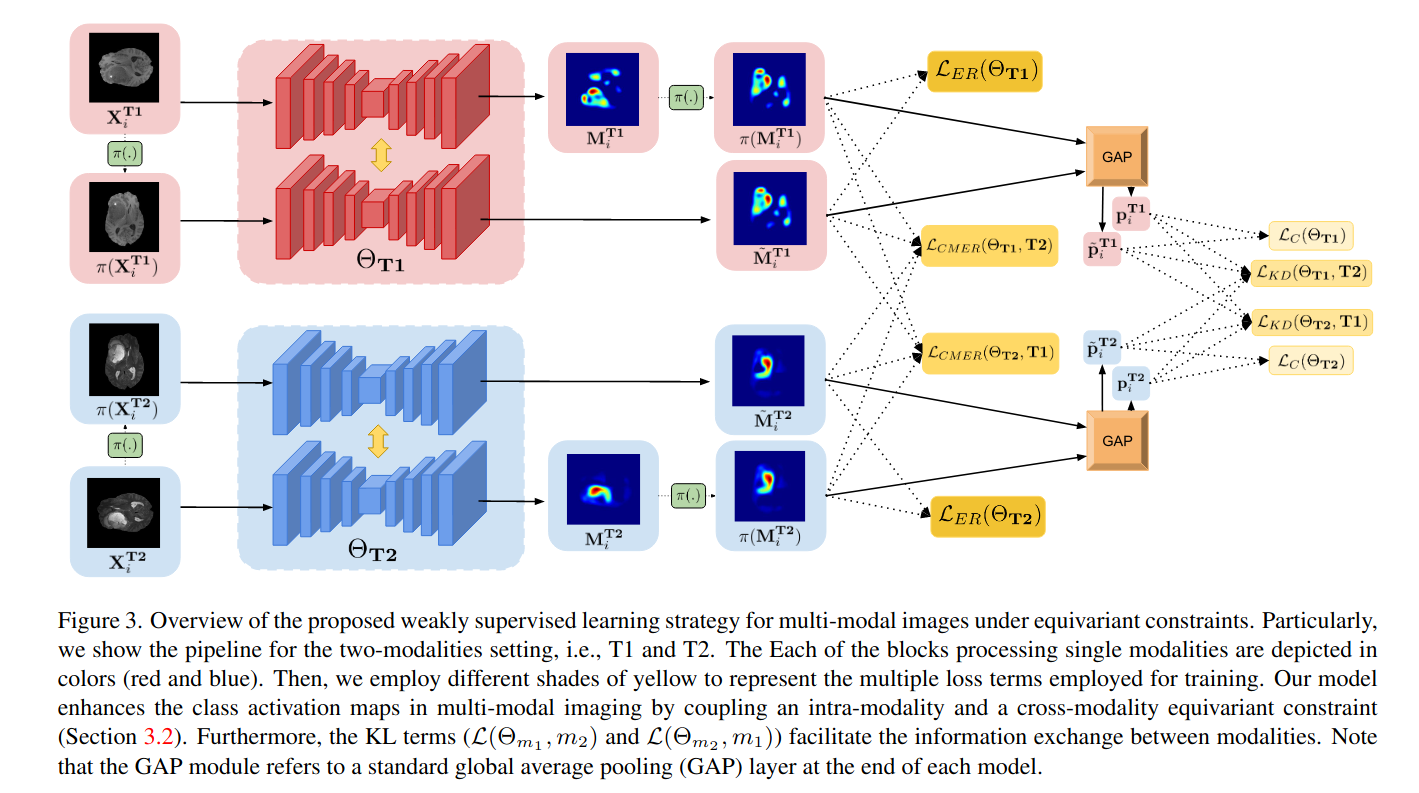
Weakly supervised learning has emerged as an appealing alternative to alleviate the need for large labeled datasets in semantic segmentation. Most current approaches exploit class activation maps (CAMs), which can be generated from image-level annotations. Nevertheless, resulting maps have been demonstrated to be highly discriminant, failing to serve as optimal proxy pixel-level labels. We present a novel learning strategy that leverages self-supervision in a multi-modal image scenario to significantly enhance original CAMs. In particular, the proposed method is based on two observations. First, the learning of fully-supervised segmentation networks implicitly imposes equivariance by means of data augmentation, whereas this implicit constraint disappears on CAMs generated with image tags. And second, the commonalities between image modalities can be employed as an efficient self-supervisory signal, correcting the inconsistency shown by CAMs obtained across multiple modalities. To effectively train our model, we integrate a novel loss function that includes a within-modality and a cross-modality equivariant term to explicitly impose these constraints during training. In addition, we add a KL-divergence on the class prediction distributions to facilitate the information exchange between modalities, which, combined with the equivariant regularizers further improves the performance of our model. Exhaustive experiments on the popular multi-modal BRATS dataset demonstrate that our approach outperforms relevant recent literature under the same learning conditions.
PDF Abstract



