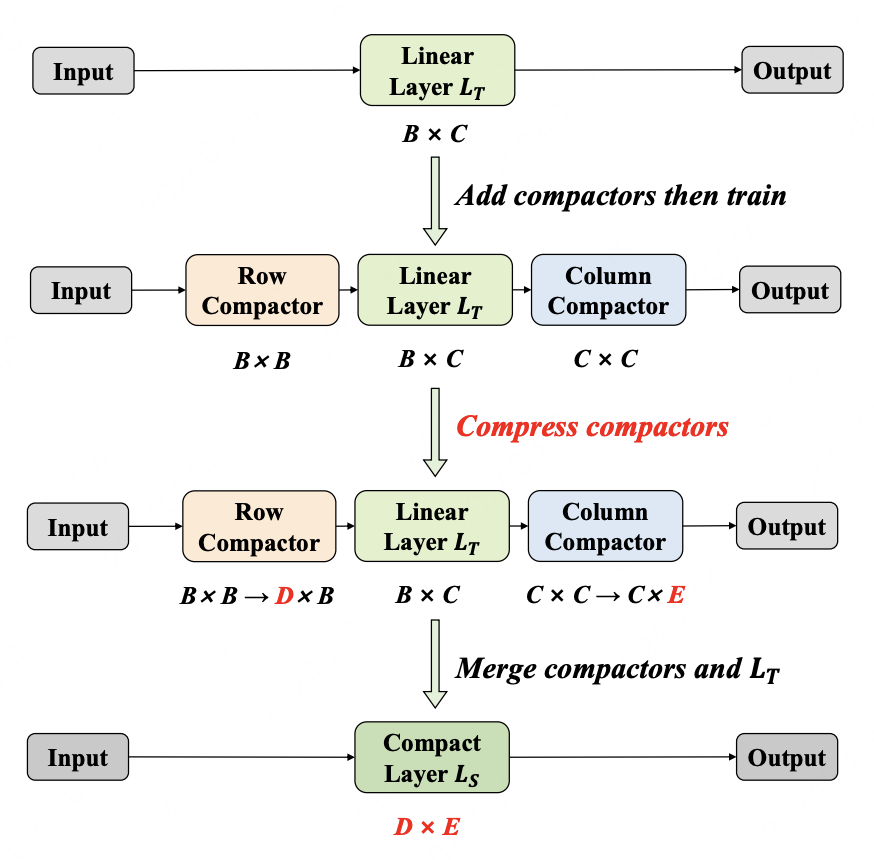
Weight-Inherited Distillation for Task-Agnostic BERT Compression
Knowledge Distillation (KD) is a predominant approach for BERT compression. Previous KD-based methods focus on designing extra alignment losses for the student model to mimic the behavior of the teacher model. These methods transfer the knowledge in an indirect way. In this paper, we propose a novel Weight-Inherited Distillation (WID), which directly transfers knowledge from the teacher. WID does not require any additional alignment loss and trains a compact student by inheriting the weights, showing a new perspective of knowledge distillation. Specifically, we design the row compactors and column compactors as mappings and then compress the weights via structural re-parameterization. Experimental results on the GLUE and SQuAD benchmarks show that WID outperforms previous state-of-the-art KD-based baselines. Further analysis indicates that WID can also learn the attention patterns from the teacher model without any alignment loss on attention distributions. The code is available at https://github.com/wutaiqiang/WID-NAACL2024.
PDF Abstract

 GLUE
GLUE
 SST
SST
 MultiNLI
MultiNLI
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
