What Actions are Needed for Understanding Human Actions in Videos?
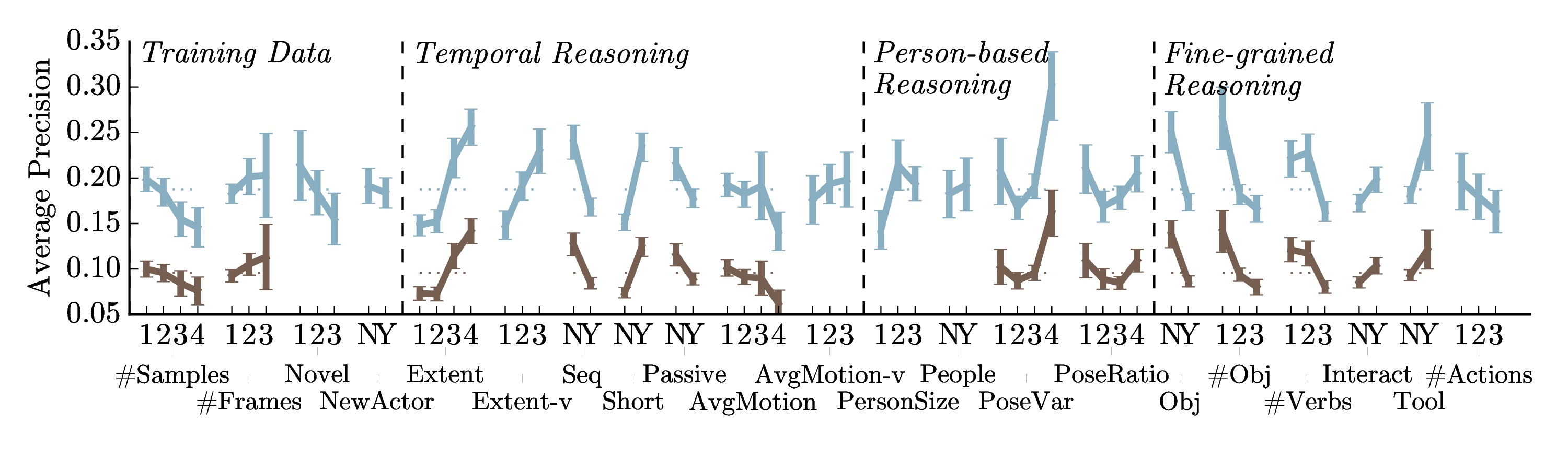
What is the right way to reason about human activities? What directions forward are most promising? In this work, we analyze the current state of human activity understanding in videos. The goal of this paper is to examine datasets, evaluation metrics, algorithms, and potential future directions. We look at the qualitative attributes that define activities such as pose variability, brevity, and density. The experiments consider multiple state-of-the-art algorithms and multiple datasets. The results demonstrate that while there is inherent ambiguity in the temporal extent of activities, current datasets still permit effective benchmarking. We discover that fine-grained understanding of objects and pose when combined with temporal reasoning is likely to yield substantial improvements in algorithmic accuracy. We present the many kinds of information that will be needed to achieve substantial gains in activity understanding: objects, verbs, intent, and sequential reasoning. The software and additional information will be made available to provide other researchers detailed diagnostics to understand their own algorithms.
PDF Abstract ICCV 2017 PDF ICCV 2017 Abstract
 UCF101
UCF101
 ActivityNet
ActivityNet
 Charades
Charades
 KTH
KTH
 MultiTHUMOS
MultiTHUMOS
