Improving generalization by mimicking the human visual diet
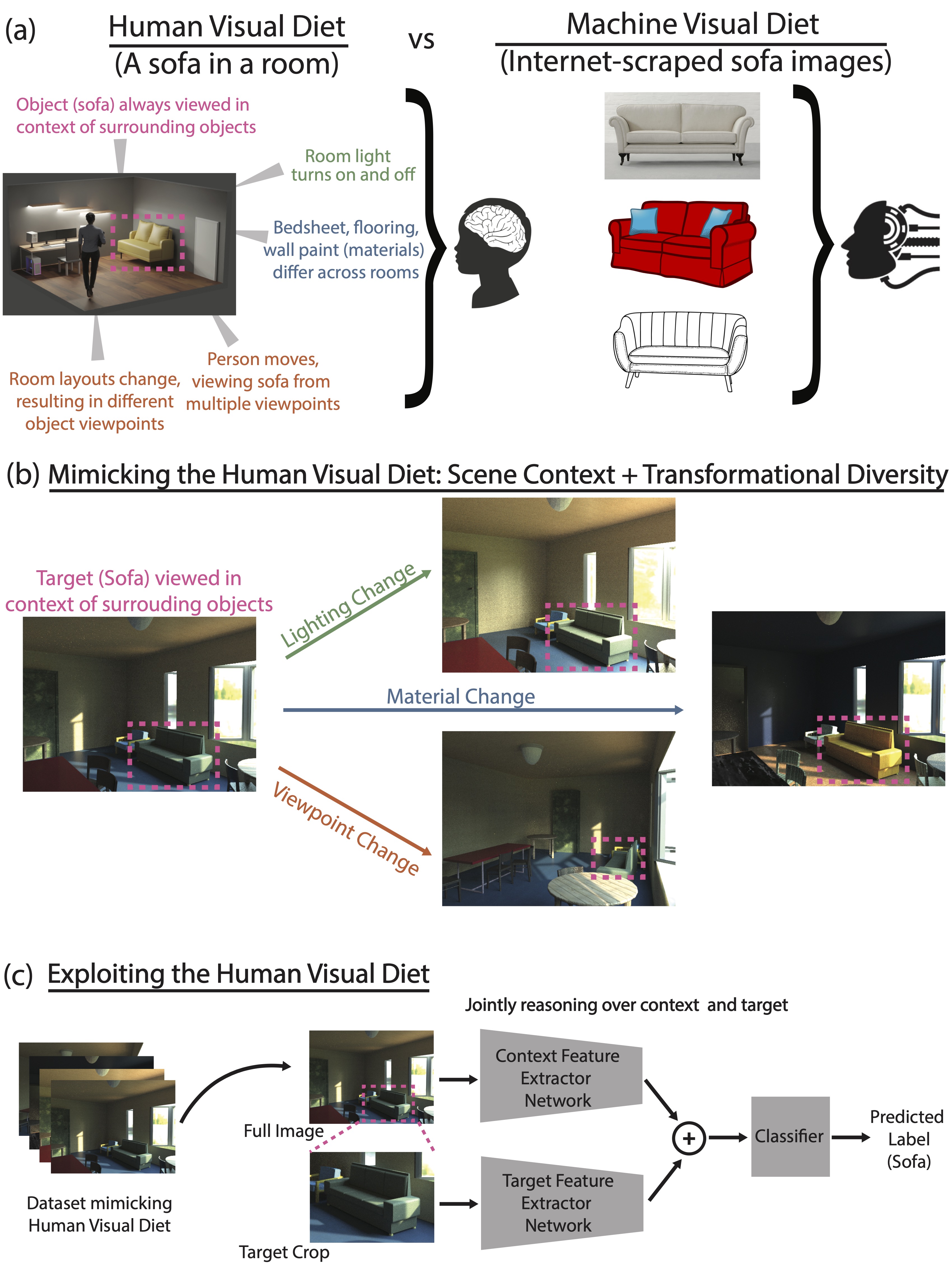
We present a new perspective on bridging the generalization gap between biological and computer vision -- mimicking the human visual diet. While computer vision models rely on internet-scraped datasets, humans learn from limited 3D scenes under diverse real-world transformations with objects in natural context. Our results demonstrate that incorporating variations and contextual cues ubiquitous in the human visual training data (visual diet) significantly improves generalization to real-world transformations such as lighting, viewpoint, and material changes. This improvement also extends to generalizing from synthetic to real-world data -- all models trained with a human-like visual diet outperform specialized architectures by large margins when tested on natural image data. These experiments are enabled by our two key contributions: a novel dataset capturing scene context and diverse real-world transformations to mimic the human visual diet, and a transformer model tailored to leverage these aspects of the human visual diet. All data and source code can be accessed at https://github.com/Spandan-Madan/human_visual_diet.
PDF Abstract

 ScanNet
ScanNet
 PACS
PACS
