What Makes Good Examples for Visual In-Context Learning?
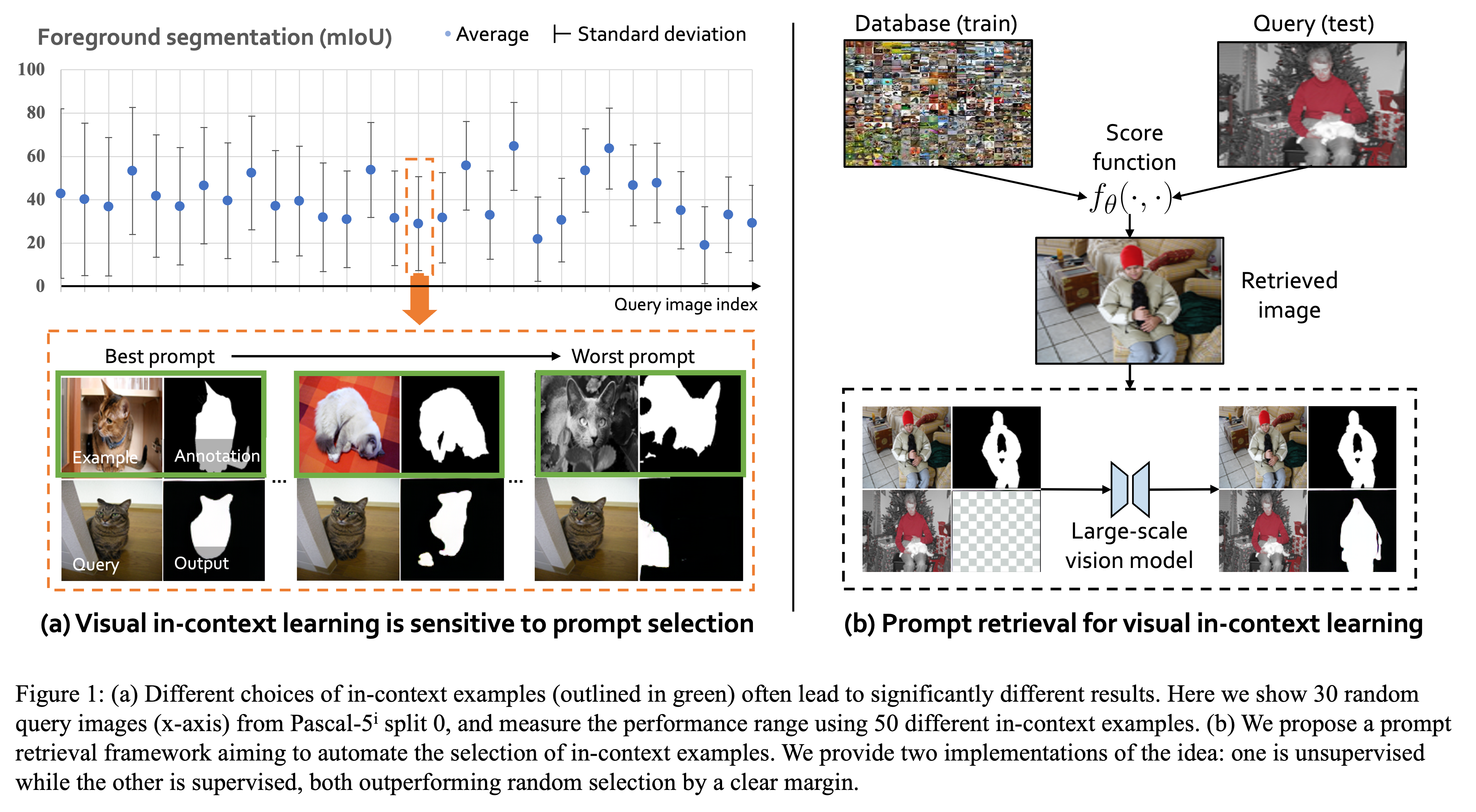
Large-scale models trained on broad data have recently become the mainstream architecture in computer vision due to their strong generalization performance. In this paper, the main focus is on an emergent ability in large vision models, known as in-context learning, which allows inference on unseen tasks by conditioning on in-context examples (a.k.a.~prompt) without updating the model parameters. This concept has been well-known in natural language processing but has only been studied very recently for large vision models. We for the first time provide a comprehensive investigation on the impact of in-context examples in computer vision, and find that the performance is highly sensitive to the choice of in-context examples. To overcome the problem, we propose a prompt retrieval framework to automate the selection of in-context examples. Specifically, we present (1) an unsupervised prompt retrieval method based on nearest example search using an off-the-shelf model, and (2) a supervised prompt retrieval method, which trains a neural network to choose examples that directly maximize in-context learning performance. The results demonstrate that our methods can bring non-trivial improvements to visual in-context learning in comparison to the commonly-used random selection.
PDF Abstract NeurIPS 2023 PDF NeurIPS 2023 Abstract

 MS COCO
MS COCO
