Guided learning for weakly-labeled semi-supervised sound event detection
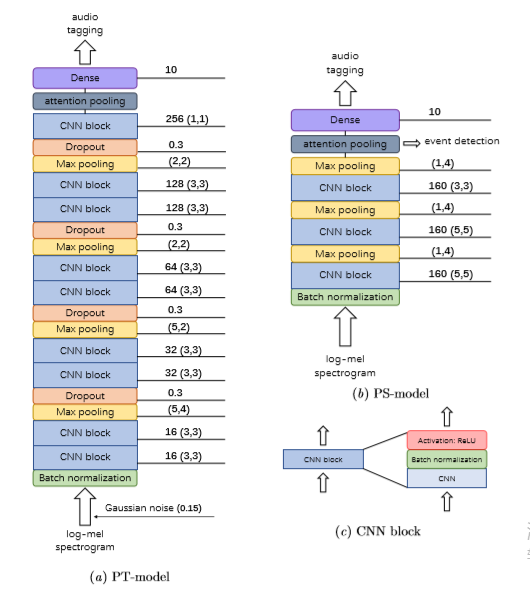
We propose a simple but efficient method termed Guided Learning for weakly-labeled semi-supervised sound event detection (SED). There are two sub-targets implied in weakly-labeled SED: audio tagging and boundary detection. Instead of designing a single model by considering a trade-off between the two sub-targets, we design a teacher model aiming at audio tagging to guide a student model aiming at boundary detection to learn using the unlabeled data. The guidance is guaranteed by the audio tagging performance gap of the two models. In the meantime, the student model liberated from the trade-off is able to provide more excellent boundary detection results. We propose a principle to design such two models based on the relation between the temporal compression scale and the two sub-targets. We also propose an end-to-end semi-supervised learning process for these two models to enable their abilities to rise alternately. Experiments on the DCASE2018 Task4 dataset show that our approach achieves competitive performance.
PDF Abstract


 DCASE 2018 Task 4
DCASE 2018 Task 4
