word2word: A Collection of Bilingual Lexicons for 3,564 Language Pairs
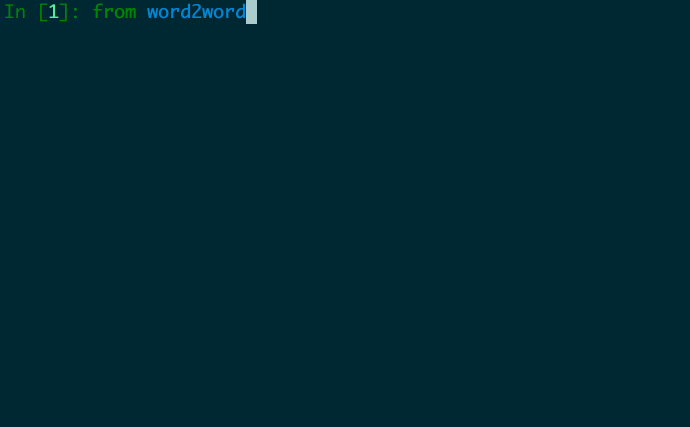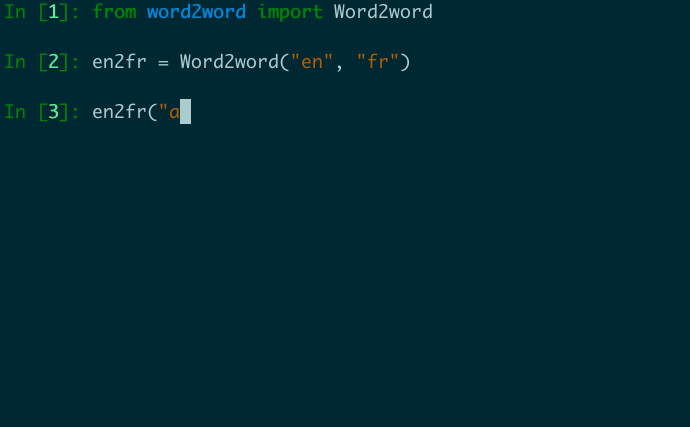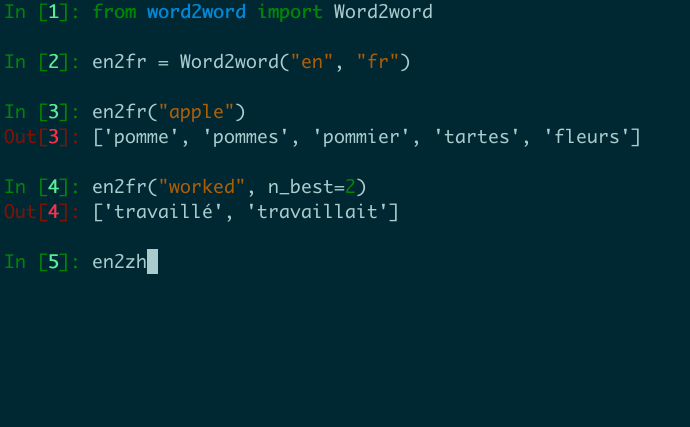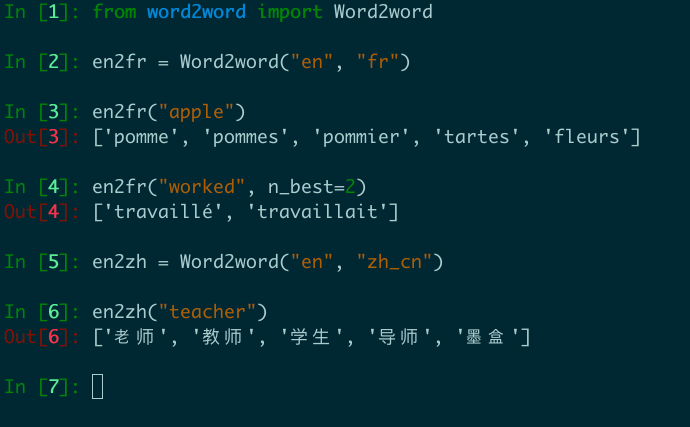
We present word2word, a publicly available dataset and an open-source Python package for cross-lingual word translations extracted from sentence-level parallel corpora. Our dataset provides top-k word translations in 3,564 (directed) language pairs across 62 languages in OpenSubtitles2018 (Lison et al., 2018). To obtain this dataset, we use a count-based bilingual lexicon extraction model based on the observation that not only source and target words but also source words themselves can be highly correlated. We illustrate that the resulting bilingual lexicons have high coverage and attain competitive translation quality for several language pairs. We wrap our dataset and model in an easy-to-use Python library, which supports downloading and retrieving top-k word translations in any of the supported language pairs as well as computing top-k word translations for custom parallel corpora.
PDF Abstract LREC 2020 PDF LREC 2020 AbstractCode
Tasks

Datasets
Introduced in the Paper:
 word2word
word2word
