You Do Not Need a Bigger Boat: Recommendations at Reasonable Scale in a (Mostly) Serverless and Open Stack
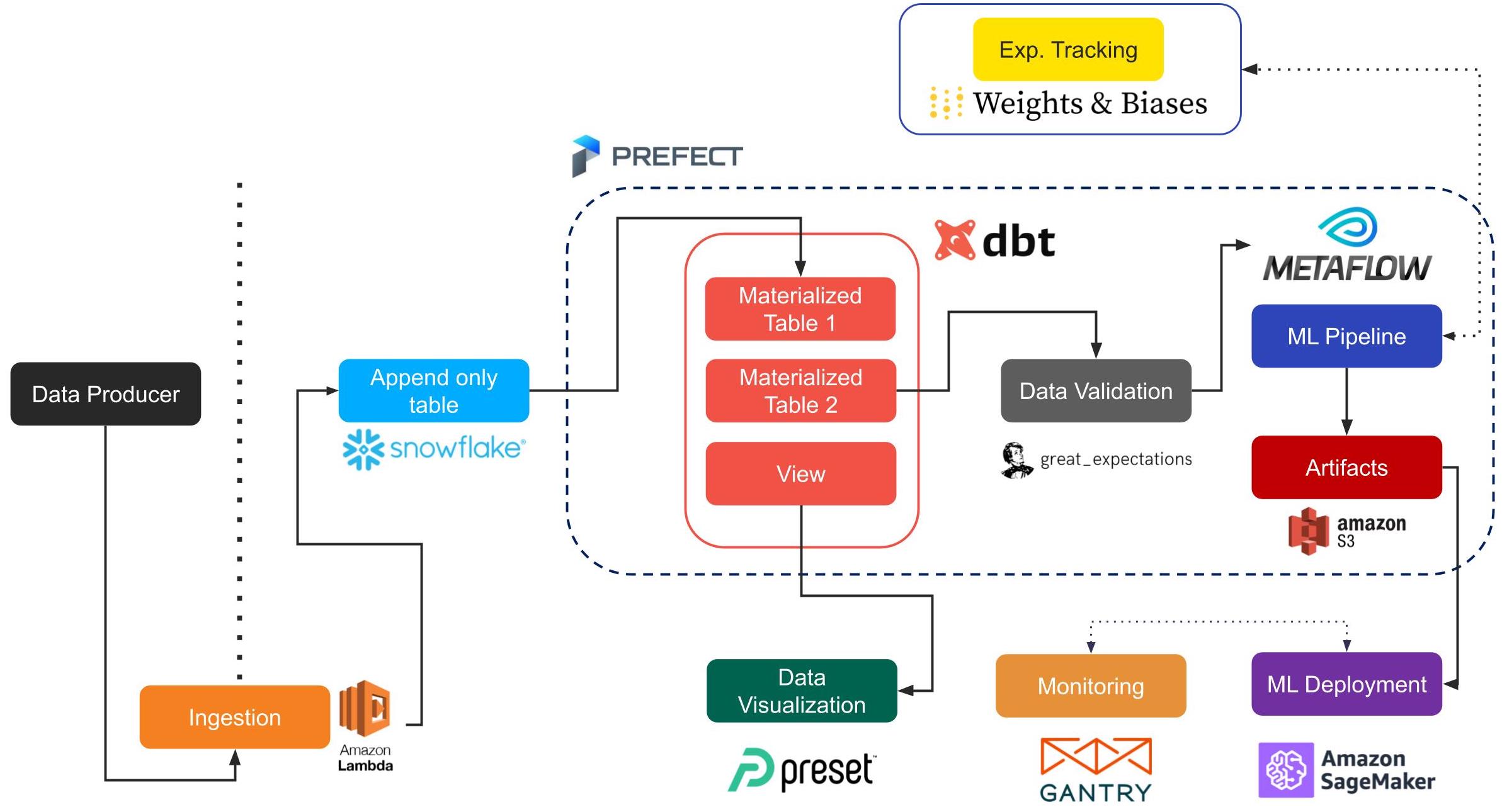
We argue that immature data pipelines are preventing a large portion of industry practitioners from leveraging the latest research on recommender systems. We propose our template data stack for machine learning at "reasonable scale", and show how many challenges are solved by embracing a serverless paradigm. Leveraging our experience, we detail how modern open source can provide a pipeline processing terabytes of data with limited infrastructure work.
PDF Abstract


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
