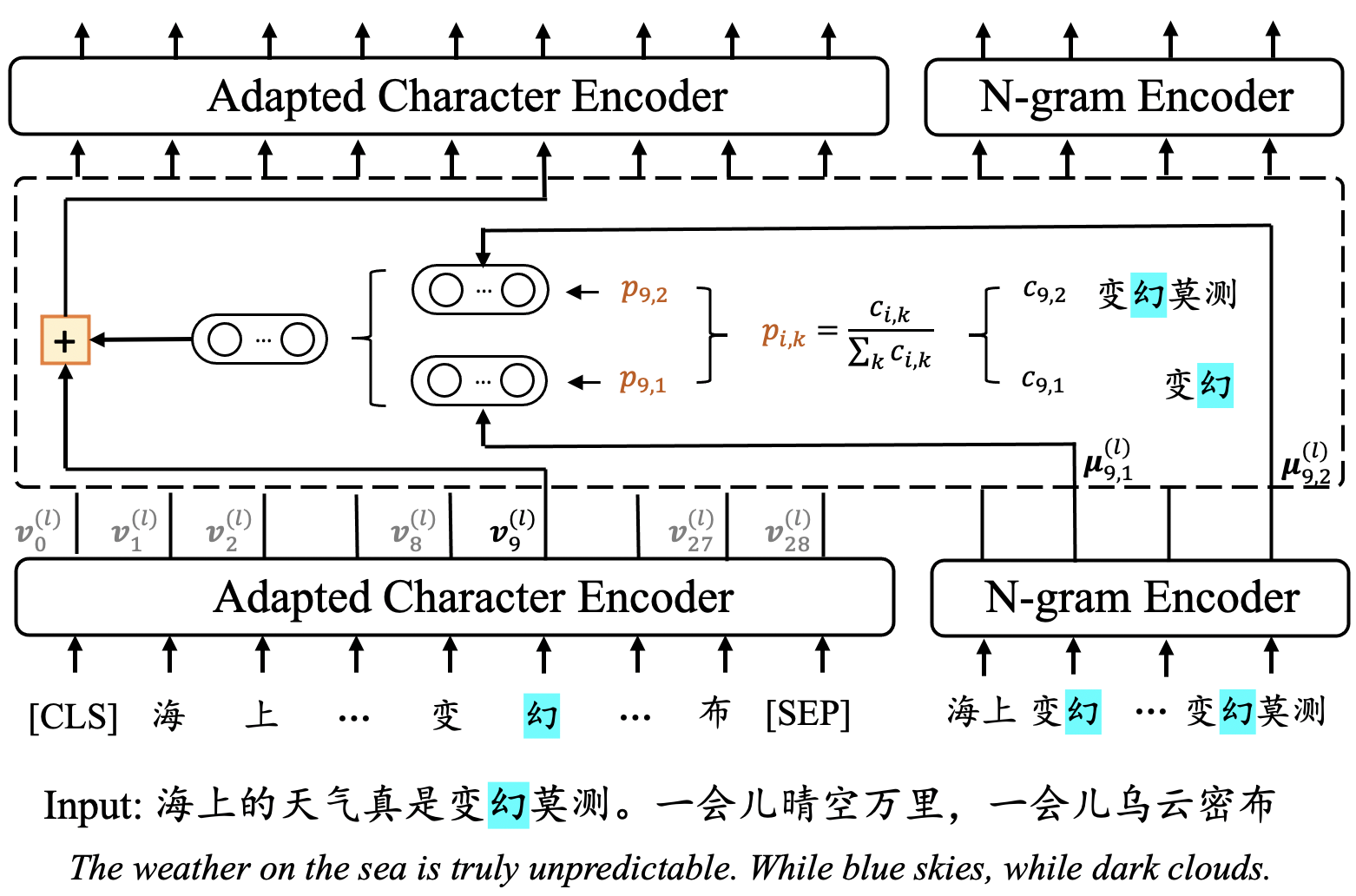
ZEN 2.0: Continue Training and Adaption for N-gram Enhanced Text Encoders
Pre-trained text encoders have drawn sustaining attention in natural language processing (NLP) and shown their capability in obtaining promising results in different tasks. Recent studies illustrated that external self-supervised signals (or knowledge extracted by unsupervised learning, such as n-grams) are beneficial to provide useful semantic evidence for understanding languages such as Chinese, so as to improve the performance on various downstream tasks accordingly. To further enhance the encoders, in this paper, we propose to pre-train n-gram-enhanced encoders with a large volume of data and advanced techniques for training. Moreover, we try to extend the encoder to different languages as well as different domains, where it is confirmed that the same architecture is applicable to these varying circumstances and new state-of-the-art performance is observed from a long list of NLP tasks across languages and domains.
PDF Abstract
 XNLI
XNLI
 CMRC
CMRC
