Zero-shot Audio Source Separation through Query-based Learning from Weakly-labeled Data
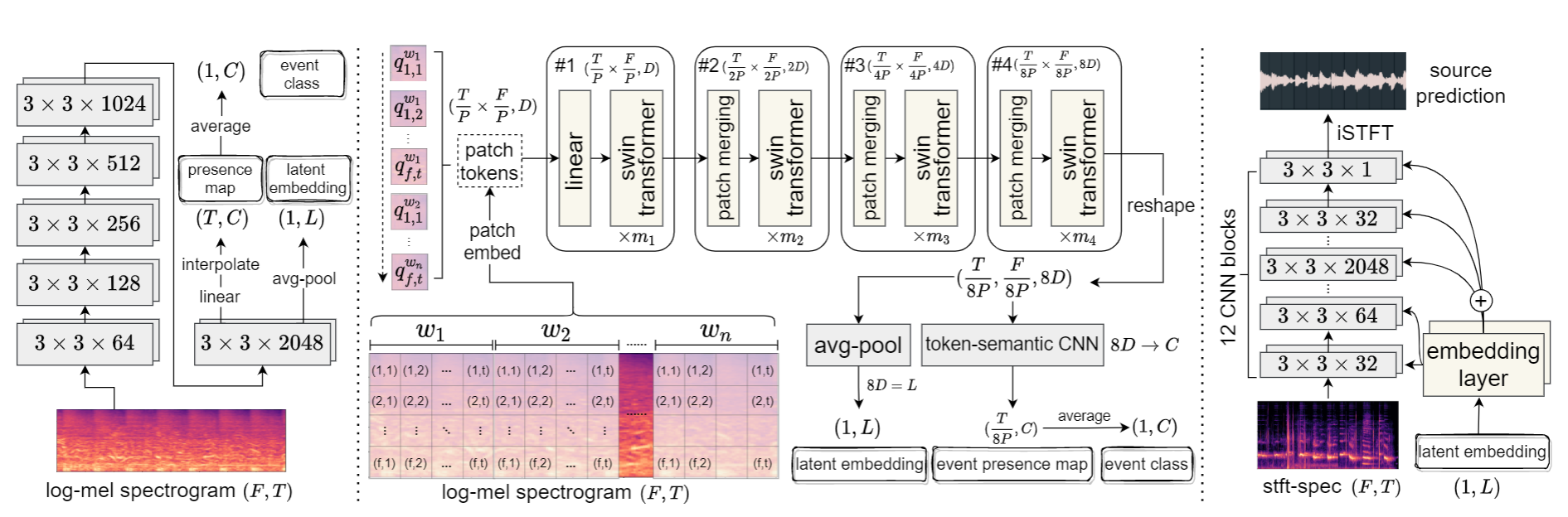
Deep learning techniques for separating audio into different sound sources face several challenges. Standard architectures require training separate models for different types of audio sources. Although some universal separators employ a single model to target multiple sources, they have difficulty generalizing to unseen sources. In this paper, we propose a three-component pipeline to train a universal audio source separator from a large, but weakly-labeled dataset: AudioSet. First, we propose a transformer-based sound event detection system for processing weakly-labeled training data. Second, we devise a query-based audio separation model that leverages this data for model training. Third, we design a latent embedding processor to encode queries that specify audio targets for separation, allowing for zero-shot generalization. Our approach uses a single model for source separation of multiple sound types, and relies solely on weakly-labeled data for training. In addition, the proposed audio separator can be used in a zero-shot setting, learning to separate types of audio sources that were never seen in training. To evaluate the separation performance, we test our model on MUSDB18, while training on the disjoint AudioSet. We further verify the zero-shot performance by conducting another experiment on audio source types that are held-out from training. The model achieves comparable Source-to-Distortion Ratio (SDR) performance to current supervised models in both cases.
PDF Abstract Replicate
Replicate


 AudioSet
AudioSet
 MUSDB18
MUSDB18

