Zero-Shot AutoML with Pretrained Models
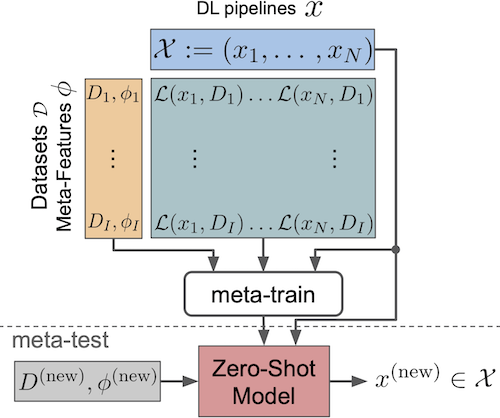
Given a new dataset D and a low compute budget, how should we choose a pre-trained model to fine-tune to D, and set the fine-tuning hyperparameters without risking overfitting, particularly if D is small? Here, we extend automated machine learning (AutoML) to best make these choices. Our domain-independent meta-learning approach learns a zero-shot surrogate model which, at test time, allows to select the right deep learning (DL) pipeline (including the pre-trained model and fine-tuning hyperparameters) for a new dataset D given only trivial meta-features describing D such as image resolution or the number of classes. To train this zero-shot model, we collect performance data for many DL pipelines on a large collection of datasets and meta-train on this data to minimize a pairwise ranking objective. We evaluate our approach under the strict time limit of the vision track of the ChaLearn AutoDL challenge benchmark, clearly outperforming all challenge contenders.
PDF Abstract

 ImageNet
ImageNet
